School of AI

باشد که دست در دست هم، آیندهی این صنعت را در میهنمان ایران بسازیم.
https://www.aparat.com/v/Pmrs8

?? ??? ?? ????? ?
We comply with Telegram's guidelines:
- No financial advice or scams
- Ethical and legal content only
- Respectful community
Join us for market updates, airdrops, and crypto education!
Last updated 1 year, 7 months ago

[ We are not the first, we try to be the best ]
Last updated 1 year, 10 months ago

FAST MTPROTO PROXIES FOR TELEGRAM
ads : @IR_proxi_sale
Last updated 1 year, 6 months ago
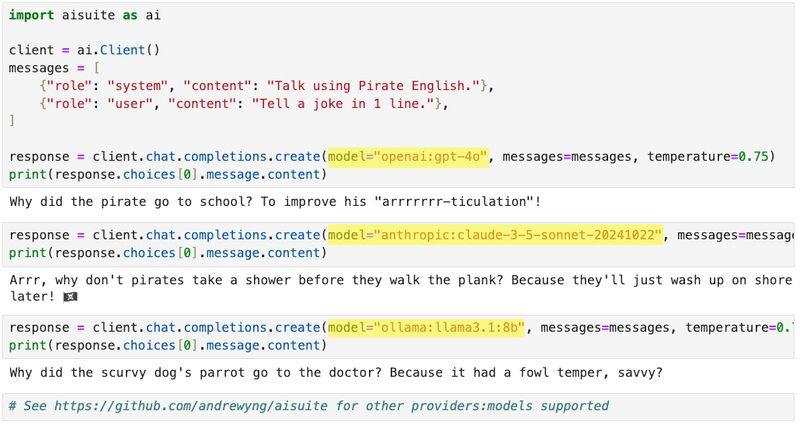
پکیج جدید از تیم اندرو انگ برای سادگی در فراخوانی مدلهای زبانی مختلف


تسلا روبووَن و روبوتاکسی را معرفی کرد...
فرمون بی فرمون!
به آینده خوش آمدید.
https://www.caranddriver.com/news/a62567491/tesla-robotaxi-reveal/

نوبل شیمی هم به سازندگان AlphaFold رسید…
شبکههای عصبی کولموگروف-آرنولد (KANs)
درشبکههای عصبی، ما معمولا بهدنبال تخمینزدن یک تابع چندمتغیرهی پیوستهی بسیار پیچیده هستیم!
در شبکههای عصبی سنتی (MLP ها)، هر سیگنال ورودی بهصورت خطی، در یک پارامتر (وزن یالها) ضرب شده، حاصل این ضربها وارد node های لایههای بعدی شده و آنجا با هم تجمیع (+) میشوند و حاصلجمع از یک تابع غیرخطیِ ثابت (Activation Function) مثل ReLU یا Sigmoid عبور میکند. قضیهی Universal Approximation میگه، از نگاه تئوری، یک MLP با فقط با یک لایهی پنهان (شامل تعداد نورون متناهی اما گاها خیلی زیاد) قادرست هر تابع چندمتغیرهی پیوسته، با هر میزان پیچیدگی را با هر دقتی که مدنظر ما باشد، تخمین بزند.
شبکههای KAN اما براساس قضیهی Kolmogorov-Arnold Representation شکل گرفتهاند که میگه، هر تابع چندمتغیرهی پیوسته (هرچند پیچیده) رو میشه بهصورت جمع تعداد متناهی (اما گاها بسیار زیاد) تابع تک متغیرهی پیوسته نوشت (بهصورت دقیق!) بنابراین، در شبکههای KAN، هر سیگنال ورودی بهجای ضرب ساده و خطی در یک پارامتر ثابت (وزن یال)، از یک تابع تکمتغیرهی پیوسته (آموزش دیدهشده) میگذرد و هر نورون فقط مسئول تجمیع (+) خروجی این توابعست. درواقع، بهجای هر وزن روی هر یال، یک تابع آموزش داده میشود و بنابراین هر نورون میتواند فقط شامل یک جمع ساده باشد.
توابعی که روی هر یال، آموزش میبینند، از نوع Spline اند. توابع اسپلاین، در بازههای مختلف و متفاوت از دامنهی خود بهشکل چندجملهایهای مجزا تعریف شده و قادرند هر منحنی (هرچند پیچیده) را تخمین بزنند. ازین رو گزینهی مناسبی برای توابع آموزشپذیر در KAN ها اند.
یکی از مشکلات شبکههای عصبی سنتی، فراموشی ناگوار (Catastrophic Forgetting) است. وقتی یک دادهی جدید را به شبکه آموزش میدهیم، تعداد بسیار زیادی پارامتر تغییر میکنند (به علت تاثیر هر تابع فعالسازی بر تعداد بسیار زیادی پارامتر روی یالهای ورودی به نورون) و ممکنست دانشی که از دادههای قبلی بهدست آمده، فراموش شود. اما در KAN ها به علت محلی بودن هر تابع اسپلاین، تعداد بسیار کمتری پارامتر تغییر کرده و فراموشی ناگوار در این شبکهها بهمراتب کمترست و این شبکهها نسبت به نویز مقاومترند.
باتوجه به قدرت بالای توابع اسپلاین در یادگیری توابع غیر خطی، و همینطور مشخصبودن یالهای بیاهمیت و قابل هرس (Pruning) از روی تابع تخمینزدهشده، تعداد لایههای مورد نیاز در کل شبکه و تعداد نورونهای هر لایه، میتوانند بهمراتب کمتر بوده و با تعداد پارامتر آموزشپذیر کمتر به Generalization بیشتر و سریعتر رسید. ازطرفی مدلهای KAN بسیار تفسیرپذیرتر بوده و میتوانند ضابطهی ریاضی تابع تخمینزدهشدهی نهایی را نیز معرفی کنند! (شکل زیر)
با این همه خوبی، آیا قراره شبکههای KAN جایگزین شبکههای فعلی در هوش مصنوعی شن؟! معلومه که نه! اساس پیشرفت شبکههای عصبی در سالهای اخیر، استفاده از GPU برای ضرب بهینهی همین ماتریسهای وزنیست که در KAN حذف شده ? بنابراین (تا جایی که فعلا میدونیم) این شبکهها برای کاربردهای علمی و مهندسی مناسباند نه پردازش الگوهای پیچیده مثل بینایی ماشین و مدلسازی زبان.
پدیدهی Double Descent
در یادگیری ماشین، میدانید که اگر مدل خیلی سادهتر از حد نیاز باشد، آموزش نمیبیند و درنهایت، پس از چند تلاش، کمبرازش (Underfit) خواهد شد. هرچه مدل را پیچدهتر کنیم (مثلا تعداد پارامترها را بیشتر کنیم)، بیشتر آموزش میبیند و قابلیت تعمیم (Generalization) آن بهتر میشود. این بهترشدن قابلت تعمیم، از روی کاهش مقدار خطا بهازای دادههای ارزیابی مشخصست.
اما این خطا تا کجا کاهش مییابد؟ آیا هرچهقدر مدل پیچیدهتر شود، خطای ارزیابی آن کمتر و قابلیت تعمیم آن بیشتر میشود؟!
در مدلهای سادهتر و سنتیتر یادگری ماشین، هرچه مدل پیچیدهتر میشد، نیاز به دادهی آموزشی بیشتری هم داشت. بنابراین با ثابت بودن سایز مجموعه داده، افزایش پیچیدگی از یکجا به بعد باعث بیشبرازش (Overfitting) مدل و حفظکردن دادهها و نویزها میشد و قابلیت تعمیم مدل از بین میرفت.
اما در دنیای مدلهای جدید (مثلا مدلهای زبانی بزرگ) شاهد آنیم که مدل هرچه بزرگتر و پیچیدهتر میشود قدرتمندتر و قابل تعمیمتر میشود! این تناقض ناشی از چیست؟!
از پدیدهی جالبی بهنام Double Descent که در شبکههای عصبی بسیار بزرگ دیده میشود. نوعی Regularization ضمنی که ظاهرا بهعلت رویهی آموزش (مثلا الگوریتم کاهش گرادیان) اتفاق میافتد. در این حالت، با پیچیدهتر شدن مدل (مثلا بیشترشدن تعداد پارامترها)، ابتدا خطای ارزیابی کاهش یافته، پس از آن در جایی با پدیدهی بیشبرازش روبهرو شده و خطای ارزیابی افزایش مییابد، اما با پیچیدهترشدن مدل، از جایی به بعد، برای بار دوم خطای ارزیابی کاهشی شده و عمومیت مدل بهتر میشود!
تصویر زیر را ببینید ???
?? ??? ?? ????? ?
We comply with Telegram's guidelines:
- No financial advice or scams
- Ethical and legal content only
- Respectful community
Join us for market updates, airdrops, and crypto education!
Last updated 1 year, 7 months ago
[ We are not the first, we try to be the best ]
Last updated 1 year, 10 months ago
FAST MTPROTO PROXIES FOR TELEGRAM
ads : @IR_proxi_sale
Last updated 1 year, 6 months ago