Уютное сообщество джавистов

туториалы для проверки знаний и обратная связь от соратников по изучению.
@viktorreh

Прислать новость, фото, видео, аудио, бересту: @in_mash_bot
Покупка рекламы: @marina_mousse
Помахаться и обсудить новости: @mash_chat
Регистрация в перечне РКН:
https://knd.gov.ru/license?id=6726d0b5db0c1931b12fc77f®istryType=bloggersPermission
Last updated 1 день, 18 часов назад

Из России с любовью и улыбкой :)
From Russia with love and a smile :)
Chat - @ShutkaUm
@Shutka_U
Last updated 2 месяца назад

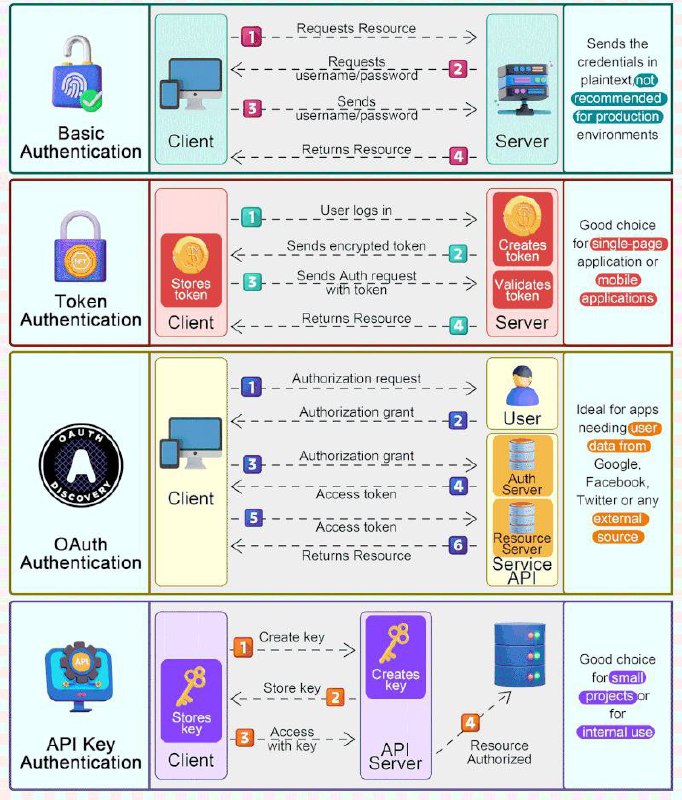
*🤫 *Некоторые популярные методы аутентификации
🔵 Базовая аутентификация:
Предполагает отправку имени пользователя и пароля с каждым запросом, но может быть менее безопасной без шифрования.
Подходит для простых приложений, где безопасность и шифрование не являются приоритетом, или при использовании защищенных соединений.
🔵 Аутентификация с помощью токенов:
Использует сгенерированные токены, такие как JSON Web Tokens (JWT), которые обмениваются между клиентом и сервером, обеспечивая повышенную безопасность без необходимости отправки учетных данных с каждым запросом.
Идеально подходит для более безопасных и масштабируемых систем.
🔵 Аутентификация OAuth:
Позволяет сторонним приложениям получать ограниченный доступ к ресурсам пользователя без раскрытия учетных данных, выдавая токены доступа после аутентификации пользователя.
Подходит для ситуаций, требующих контролируемого доступа к ресурсам пользователя сторонними приложениями или сервисами.
🔵 Аутентификация с использованием API-ключей:
Назначает уникальные ключи пользователям или приложениям, которые отправляются в заголовках или параметрах; несмотря на простоту, может не обладать всеми преимуществами безопасности, как методы на основе токенов или OAuth.
Удобна для простого контроля доступа в менее чувствительных средах или для предоставления доступа к определённым функциям без необходимости предоставления разрешений, привязанных к конкретному пользователю.
💬 Какой метод аутентификации вы считаете наиболее эффективным с точки зрения обеспечения безопасности и удобства использования в ваших приложениях?

👩💻 Открытый урок «Интернационализация и локализация в приложениях Spring»
🗓 25 ноября в 20:00 МСК
🆓 Бесплатно. Урок в рамках старта курса «Разработчик на Spring Framework» от Otus.
Узнайте, как эффективно реализовать интернационализацию и локализацию в Spring-приложениях.
На вебинаре разберем:
✔️работу с классом Locale, использование MessageSource в Spring Boot и без него;
✔️ способы хранения и смены локали в веб-приложениях;
✔️ локализацию в шаблонах Thymeleaf и сообщений Bean Validation;
✔️ обсудим, почему не стоит локализовывать исключения;
✔️ проанализируем исходный код для лучшего понимания процессов.
🔗 Ссылка на регистрацию: https://vk.cc/cECfzL
Реклама. ООО «Отус онлайн\-образование», ОГРН 1177746618576

**Kotlin Design Patterns and Best Practices
Автор: Alexey Soshin
Год издания:** 2022

*🗑 *Понимание различных сборщиков мусора в Java:
🔵 Serial Garbage Collector: Лучший вариант для однопоточных приложений с небольшими кучами. Он использует один поток для выполнения как малых, так и больших сборок мусора, что приводит к значительным паузам, но минимальной нагрузке на систему.
🔵 Parallel Garbage Collector: Подходит для приложений с высокими требованиями к пропускной способности. Использует несколько потоков для выполнения как малых, так и больших сборок мусора, уменьшая время пауз, но при этом увеличивая использование CPU.
🔵 Concurrent Mark-Sweep (CMS) Garbage Collector: Разработан для минимизации пауз за счёт выполнения основной части работы по сборке мусора параллельно с выполнением приложений. Подходит для приложений, где критически важна низкая задержка.
🔵 G1 Garbage Collector: Сбалансированный сборщик мусора, который стремится обеспечить предсказуемое время пауз, разделяя кучу на регионы и выполняя сборку мусора поэтапно. Является хорошим выбором по умолчанию для большинства приложений.
🔵 Z Garbage Collector и Shenandoah: Сборщики мусора с ультранизкой задержкой, разработанные для работы с большими кучами. Основная часть работы по сборке мусора выполняется параллельно, что позволяет минимизировать время пауз даже при очень больших кучах.

**Data Wrangling Using Pandas, SQL, and Java
Автор: Oswald Campesato
Год издания:** 2023

Ссылки на методы в JavaЛямбды в Java полезны во многих направлениях. Лямбда-выражения можно использовать для более простых задач, а лямбда-утверждения — для более сложных. Лямбды могут вызывать другие методы для текущего объекта (this) и объектов, которые находятся в области видимости, таких как текущий элемент итерации и конечная локальная переменная за пределами лямбды. Лямбду всегда можно упростить, поместив код в другой метод.Читать статью
От JDBC до Spring Data: часть 2
В этом посте расскажу про популярные модули Spring Data и подскажу важный нюанс при изучении Hibernate.
Spring Data JPA
Hibernate вызвал вау-эффект тем, что взял на себя маппинг и простейшие SQL запросы.
Spring Data JPA пошёл дальше и избавил разработчика от унылых конфигов и возни с сессиями, плюс генерирует более сложные SQL запросы.
Всё очень круто (без шуток), но есть нюанс.
Ванильный Hibernate подразумевает, что пользователь знаком с деталями реализации — умело работает с кэшами 1 и 2 уровня, различает persist/save/merge, использует нужные типы данных и тд.
А вот JPA определяет только интерфейс доступа к данным. Поэтому в Spring Data JPA многие хибернейт фичи не используются.
Пример — ленивая загрузка коллекций и кэш 1 уровня. Spring Data в общем случае при каждом обращении к репозиторию создаёт новую сессию. Кэширования в итоге нет, а при загрузке коллекций ловим эксепшн.
Кэш 2 уровня и EntityGraph поправят ситуацию, но это уже продвинутый уровень:) Недостаточно пользоваться абстракцией "репозиторий", надо знать и Hibernate, и как Spring использует Hibernate.
Практический совет — если что-то читаете по хибернейту, уточняйте, как это работает в Spring Data и работает ли вообще.
Для простых сервисов Spring Data JPA существенно упрощает жизнь. Для сложных тоже, но требует больше знаний.
Spring Data JDBC
— альтернатива Spring Data JPA. Под капотом у него JDBC без посредничества Hibernate.
Интерфейс такой же — пользователь работает с репозиторием и размечает классы аннотациями типа @Id или @Column.
JDBC проще, у него нет кэшей, ленивой загрузки, каскадных операций и автоматического сохранения. Код становится предсказуемым, но многие вещи нужно делать явно.
Отдельного внимания заслуживает работа с зависимыми сущностями в DDD стиле. А в этом докладе показан наглядный пример и больше различий Spring Data JPA/JDBC.
Важный момент! Не путайте две библиотеки:
🌸 Spring JDBC упрощает работу с соединениями. Запросы, маппинг сущностей, управление транзакциями пишет разработчик
🌹 Spring Data JDBC даёт следующий уровень абстрации — репозиторий. Работа c запросами, маппингом и транзациями упрощается за счёт аннотаций
MyBatis
часто упоминается как альтернатива Hibernate. Называет себя persistence framework, а не ORM, но занимается тем же — помогает писать меньше кода по перегону данных между БД и приложением.
Основное отличие MyBatis от хибернейта — все SQL-запросы пишутся явно, и внутри можно писать if и foreach блоки.
MyBatis в целом ничего, но редко встречается. Причины просты:
❌ Нет Spring Data модуля, только Spring Boot Starter. Писать руками нужно гораздо больше
❌ В MyBatis есть аннотации, но документация и большинство статей используют XML. Выглядит несовременно👨🦳
Итого
⭐️ Spring Data * берёт на себя конфиги, работу с сессиями, генерацию некоторых запросов
⭐️ Spring Data JPA упрощает работу с Hibernate
⭐️ Spring Data JDBC предлагает похожий интерфейс, но на основе JDBC
⭐️ MyBatis для тех, кто хочет чего-то другого
Что выбрать?
Функционально Spring Data JPA/JDBC и MyBatis похожи, но со своими нюансами. Адекватных и современных бенчмарков в интернете нет. Статьи вроде "Hibernate vs MyBatis" очень поверхностные, не тратьте на них время.
На практике выбор делается почти случайно. Что затащат в проект на старте, то и используется:)
От JDBC до Spring Data: часть 1
Общение с базой данных связано с огромным количеством технологий — навскидку вспоминаем JDBC, JPA, Hibernate и Spring Data. Они тесно переплетены, и не всегда люди чётко понимают, что есть что и зачем нужно.
В ближайших постах разложу по полочкам основные технологии по работе с данными.
❓Почему всё так сложно? Почему нельзя сохранить всё как есть?
Приложение использует оперативную память и представляет данные в виде объектов. Можно работать с любым объектом в любой момент — чтение и запись происходят быстро. Минус оперативки — когда приложение завершается, память освобождается, и данные пропадают.
Чтобы данные пережили приложение, они записываются в постоянную память. Хранением и организацией данных занимается БД.
В оперативке данные лежат кое-как — где место нашлось, там объект и создаётся. В постоянной памяти данных много, всё упорядочено и оптимизировано. Поэтому модели данных в БД и приложении иногда отличаются.
А ещё БД — это отдельное приложение. В итоге для сохранения/извлечения данных нужна куча дополнительной работы:
🔸 открыть соединение
🔸 составить SQL запрос
🔸 передать в запросе данные из приложения
🔸 преобразовать ответ БД в java объект
🔸 закрыть соединение
JDBC
— стандартные java методы, которые выполняют все пункты выше. Все инструменты по работе с БД под капотом используют как раз JDBC.
Работа с соединениями и преобразование данных — утомительная работа. Поэтому и появляются библиотеки, облегчающие этот труд.
Spring JDBC
берёт на себя работу с соединениями. Разработчик всё так же составляет запросы, передаёт параметры и преобразует ответы в java объекты.
ORM
Object Relational Mapping — преобразование данных (mapping) из java объектов в сущности БД и обратно.
Формально, ORM — просто название процесса. В случае JDBC весь ОRМ разработчик делает вручную.
На практике под ORM подразумевают ORM библиотеку/фреймворк — какой-нибудь инструмент, который берёт на себя часть работы по запросам и преобразованию данных.
Hibernate
— самая популярная ORM библиотека. Составляет простые SQL запросы и преобразует данные. Упростил жизнь многим и заслужил их любовь❤️
В хибернейте не всё идеально:
▪️ Работа с соединениями (сессиями) остаётся на пользователе
▪️ Для корректной работы надо знать внутрянку (dirty session, как разруливаются отношения и тд).
Сложно не признать, что Hibernate великолепен. Ворвался на олимп ORM библиотек в 2001 году и до сих пор оттуда не слезает🏆
JPA
Сейчас большинство приложений базируются на спринге, но 10-15 лет назад приложения часто опирались на Java ЕЕ. В те года ORM Java ЕЕ выглядел сложно — для каждой сущности требовались несколько классов и кучка интерфейсов.
Hibernate выглядел привлекательно, но нельзя просто взять и добавить библиотеку в проект. Во вселенной Java EE всё работает через спецификации — стандартные интерфейсы.
Поэтому появилась новая спека по ORM — Java Persistence API или JPA. С небольшими отличиями почти полностью списана с хибернейта. Вскоре Hibernate подстроился под JPA и стал использоваться в Java EE.
Итого
⭐️ JDBC — базовое API по работе с БД
⭐️ ORM — преобразование данных между приложением и БД. На практике под “у нас на проекте ORM” имеют в виду, что используется ORM библиотека, например, Hibernate
⭐️ JPA — спецификация по ORM. Набор интерфейсов, аннотаций и описание, как всё должно работать. Не включает в себя конкретную реализацию
⭐️ Hibernate — популярная ORM библиотека, реализующая JPA
В следующем посте распишу вариации Spring Data, и почему материалы по хибернейт могут не соответствовать реальности.
](/media/attachments/jav/javaarchivebooks/312.jpg)
💡Задача: Сумма вдоль столбцов
Условие: дается квадратная матрица, необходимо вычислить минимальную сумму вдоль столбца.
Есть условие на движение вдоль столбца есть ограничение: можно перемещаться на ячейку вниз лишь по диагонали или строго вниз.
**Пример:
Ввод: matrix = [[2,1,3],[6,5,4],[7,8,9]]
Вывод: 13
Объяснение: во вложении*Решение
🚀 Юнит-тестирование вашей Java-архитектуры 🚀
@archtests - это мощная библиотека Java, которая позволяет писать модульные тесты для обеспечения соблюдения архитектурных ограничений и правил в вашем коде.
Прислать новость, фото, видео, аудио, бересту: @in_mash_bot
Покупка рекламы: @marina_mousse
Помахаться и обсудить новости: @mash_chat
Регистрация в перечне РКН:
https://knd.gov.ru/license?id=6726d0b5db0c1931b12fc77f®istryType=bloggersPermission
Last updated 1 день, 18 часов назад
Из России с любовью и улыбкой :)
From Russia with love and a smile :)
Chat - @ShutkaUm
@Shutka_U
Last updated 2 месяца назад