Сиолошная

Более подробно смотри в первом сообщении в канале (оно закреплено). А еще у нас есть чат! Заходи: https://t.me/+i_XzLucdtRJlYWUy


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 4 days ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago
 рубрику …](/media/attachments/see/seeallochnaya/1973.jpg)
На канале Y Combinator возродили рубрику How To Build The Future. Раньше её вёл Sam Altman, а теперь он стал приглашённым гостем!
Поговорили с текущим президентом YC про ранние дни в сфере стартапов и OpenAI, про масштабирование моделей и бизнеса, тезисно:
— Сравнили YC и Stanford University по окружению; в YC более качественная «тусовка» вокруг, которая побуждает чем-то заниматься и вкалывать. Sama говорит, что peer pressure (давление от окружения) будет всегда, и с этим ничего не поделать; но что можно сделать — так это выбрать правильных пиров. И в YC по итогу куда более интенсивно.
— Вспомнили первые дни OpenAI. Sama говорит, что уже в первые дни появилось видение, чем хочется заниматься. На флип-чарте кто-то написал три цели: 1) разобраться, как правильно делать обучение без учителя (без размеченных данных, как сейчас большую часть времени тренируется GPT) 2) разобраться с Reinforcement Learning (другой способ обучения, тоже используется) 3) никогда не иметь больше 120 человек в команде. В первых двух целях преуспели, по третьей промахнулись — ещё в начале 23-го года в OpenAI было примерно 375 человек (лол, про это был самый первый пост в этом канале!), сейчас уже более 1700.
— Вместе с этим у основателей компании было несколько — одно из core beliefs: DL works and it works better with scale. Не знали как предсказать два ключевых верования: Deep Learning (обучение нейронок) работает, и оно становится лучше с масштабированием. По второму — был буквально религиозный уровень веры в то, что оно будет продолжать работать лучше. В то время в области машинного обучения это не был консенсусом, а за разговоры про AGI можно было словить критику и насмешки. На январь 2016-го года ещё даже не было AlphaGo (она сыграла первые игры с чемпионами, но информация не была опубликована), чтобы говорить про какие-то крупные успехи, кроме распознавания изображений.
— OpenAI изначально делали большую ставку на что-то одно вместо того, чтобы распыляться и пробовать везде понемногу. По итогу это сыграло, и сейчас фактически все игроки следуют за ними. Частично такой фокус схож с тем, чему сам Sam учил стартапы в YC: одно направление, результат, масштабирование.
— но это не значит что они прошли прямо самым коротким путем, были ответвления, но зато они принесли ценные научные знания (эксперименты с играми, с робо-рукой)
— Пересказал историю до GPT-1, как она получилась, и про роль исследователя Alec Radford в ней. Если вам этот кусок показался интересным, то напомню, что у меня есть бесплатный набор лекций «полная история GPT» на YouTube, где в первых видео рассказывается про предысторию, что там было и на какие мысли натолкнуло.
— Термин AGI стал очень шумным и многозначным; Летом в OpenAI ввели взамен систему из 5 уровней. Ранее Bloomberg писал, что якобы на июльской презентации модели прототипа o1 было заявлено о переходе с первого уровня (чатботы) на второй (reasoners, сущности, способные к рассуждениям). Но это были только слухи, и вот теперь Altman на камеру это подтвердил — они считают, что о1 достигла второго уровня в их шкале, а дальше идут ИИ-агенты. И что скоро нас ждёт прогресс в отношении этого шага — ждём!
Подборка каналов об искусственном интеллекте и машинном обучении от издания «Системный Блокъ»
Data Science, машинное обучение, искусственный интеллект — cегодня о них пишет каждый. Но как найти тех, кто действительно разбирается? «Системный Блокъ» собрал каналы экспертов в сфере ИИ, DS и ML
— @ai_newz — эйай ньюз
Модели для будущих робо-гуманоидов от Nvidia, знакомство с основателями стартапа Mistral, трюки в промптинге языковых моделей и списки книг для изучения машинного обучения — в канале найдете новости из сферы ИИ и советы по входу в неё. Автор канала Артём получил PhD в лаборатории университета Гейдельберга, где сделали Stable Diffusion, работает Staff Research Scientist в команде LLaMA в одной из крупнейших IT-компаний мира и пишет о своем опыте
— @seeallochnaya — Сиолошная
Понятные разборы исследований по нейросетям, охватывающие темы от воздействия на образование до разборов внутренностей LLM. Обзоры новостей, которые влияют на будущее индустрии ИИ: от экономических аспектов до ядерной энергетики для подпитки датацентров. Канал ведёт Игорь Котенков — руководитель ИИ-отдела в международной компании; в прошлом занимался машинным обучением в AliBaba, Яндексе и X5 Retail; автор множества популярных статей-разборов и лекций, подходящих любой аудитории
— @gonzo_ML — gonzo-обзоры ML статей
Интересны обзоры специализированных статей об искусственном интеллекте и машинном обучении, анонсы и анализ больших языковых моделей? Этот проект — для вас! Среди последних публикаций: отражение малых языков в больших языковых моделях и системах машинного перевода, лекции о проблемах сознания и тезисы отчета о состоянии сферы ИИ. Канал ведут CTO Intento Григорий Сапунов, ex-руководитель разработки Яндекс-Новостей, и Алексей Тихонов, ex-аналитик в Яндексе, автор Яндекс-автопоэта и Нейронной обороны
— @boris_again — Борис опять
Здесь вы найдете материалы об IT и программировании, поиске работы в Machine Learning’е, обзоры исследований в области ИИ. Автор работает в eBay, преподает машинное обучение, делится профессиональным и личным, шутит и философствует. Например, рассказывает, как развивать самоконтроль, берет интервью у коллег о карьере в технологическом секторе и делает подборки русскоязычных LLM
— @rybolos_channel — Kali Novskaya
Применение языковых моделей в науке, история GPT в стиле Хармса, подборки курсов по NLP, а также анализ угроз открытым данным, на которых обучаются языковые модели. Канал ведет Татьяна Шаврина — лингвист, менеджер исследовательской команды в LLAMA, большая сторонница опенсорса и открытых данных. Она рассказывает о современных LLM и NLP-исследованиях, важности открытых технологий, этике искусственного интеллекта и сложных вопросах интеллектуальной собственности
— @tech_priestess — Техножрица
Канал для тех, кому интересны математика, разработка и исследования машинного обучения. Создательница проекта работает старшим академическим консультантом в Huawei и рассказывает об исследованиях, в которых участвует (например, о границе между текстами, написанными человеком и ИИ), пишет о трансформерах, NLP, анализе данных и глубоком обучении
— @dealerAI — DealerAI
Как связать дообучение на основе фидбэка от людей с дообучением на ИИ-фидбэке? Чем можно улучшить RAG? Какие маленькие модели выигрывают у больших аналогов? Автор канала Александр Абрамов — создатель языковых моделей, победитель соревнований в Kaggle и хакатонов по Data Science, а также тимлид нескольких ML-команд, которые решают задачи обработки естественного языка и интегрируют LLM в прикладные проекты. В канале есть посты обо всем, что связано с DS, NLP и машинным обучением: например, о новых LLM и галлюцинациях нейросетей
— @sysblok — Системный Блокъ
Как ИИ помогает читать древние тексты? Почему лингвисты проиграли последнюю битву за NLP? Как связаны машинное обучение и японская уличная мода? «Системный Блокъ», основанный выходцами из RND отдела ABBYY, рассказывает о том, как трансформируется культура в век больших данных — что происходит на стыке IT, гуманитарных наук и Data Science или как ML применяют в естественных и гуманитарных науках
Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models С 2014-го года в Google существует проект Google Zero, в рамках которого экспертами проводится аудит уязвимостей в программах. Существует большое количество инструментов…
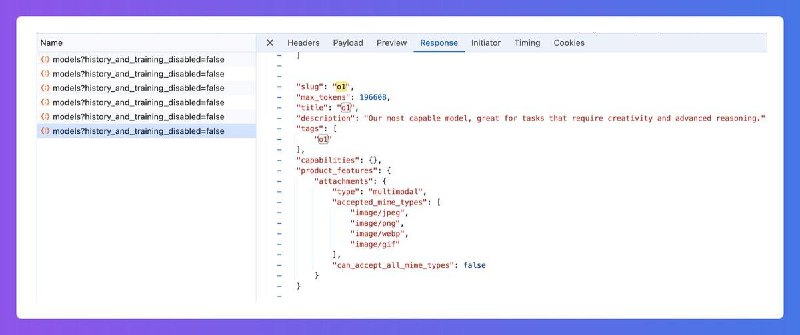
1) У модели в карточке подпись «Our most capable model, great for tasks that require creativity and advanced reasoning»
2) В доп. информации написано 196,608 max tokens (урааа, наконец-то рост!). У других моделей: o1-preview 57,768, o1-mini — 98,304
3) модель в моих тестах и у людей в комментариях думает над задачами дольше (ну конечно, хозяева же разрешили больше токенов писать!)
4) Указано, что принимает jpeg, png, webp и gif, по крайней мере пока. Правда, кто-то уже пытался залить webp и не вышло, что странно.;
UPD: напомню, почему это важно — полноценная o1 значимо лучше во многих задачах, чем preview-версия, так вдобавок ещё и по картинкам сможет делать более глубокие выводы (так как начинает рассуждать)
Measuring short-form factuality in large language models
Не статья, но по сути открытый бенчмарк от OpenAI.
Открытой проблемой в области ИИ является тренировка моделей на выдачу ответов, которые фактически верны. Современные языковые модели иногда выдают ложную информацию, не подкрепленную доказательствами (известно как «галлюцинации»). LLM, которые выдают более точные ответы с меньшим количеством галлюцинаций, более надежны, и могут быть использованы в более широком спектре задач и приложений.
Фактичность — сложный критерий, поскольку его трудно измерить: оценка любого произвольного утверждения — сложная задача, так как языковые модели могут генерировать длинные ответы, содержащие десятки фактических утверждений (не все из которых релевантны вопросу, но тем не менее могут быть правдивыми).
В SimpleQA OpenAI сосредоточились на коротких запросах. Всего в бенчмарке 4326 вопросов на разные темы (больше всего про технологии и науки, но есть и про музыку, историю).
Чтобы попасть в датасет, каждый вопрос должен был соответствовать строгому набору критериев:
— он должен иметь единственный, неоспоримый ответ, который легко верифицировать
— ответ на вопрос не должен меняться с течением времени; — большинство вопросов должны были вызывать галлюцинации у GPT-4o или GPT-3.5
Вопросы были заготовлены разными исполнителями в соответствии с требованиями выше. Затем второй эксперт отсматривал вопросы, не видя ответ, и пытался найти ответ. Если ответы не совпадали — такой вопрос не добавляли.
Для 1000 случайных вопросов привлекли ещё третьего эксперта, чтобы оценить чистоту данных. Его ответ совпадал с ответами первых двух в 94.4% случаев. 2.8% ошибок были вызваны невнимательной работой третьего эксперта, и 2.8% были вызваны реальными проблемами с вопросом (например, неоднозначные вопросы; или разные веб-сайты, дающие противоречивые ответы). Таким образом, OpenAI оценивают собственную частоту ошибок для этого набора данных примерно в 3%.
Примеры вопросов:
— Which Dutch player scored an open-play goal in the 2022 Netherlands vs Argentina game in the men’s FIFA World Cup?
— Who received the IEEE Frank Rosenblatt Award in 2010?
— What day, month, and year was Carrie Underwood’s album “Cry
Pretty” certified Gold by the RIAA?
— What is the first and last name of the woman whom the British
linguist Bernard Comrie married in 1985?
Пачка новостей на сегодня: — Reuters узнали новые детали о планах OpenAI на производство собственных чипов. Уже было известно, что калифорнийская компания заключила партнёрство с Broadcom (они делают TPU для Google уже больше 7 лет). «OpenAI рассматривали…
Помните пару месяцев назад многие смотрели на ответы LLMок на запрос «Что больше, 9.8 или 9.11?»? Вот в этом блоге-анонсе инструмента для механистической интерпретируемости авторы пытаются понять, почему так происходит, анализируя внутренние состояния модели. Про интерпретируемость и анализ внутренностей я недавно писал лонг, если пропустили — рекомендую к прочтению.
Так вот, что делается в инструменте:
1) вы выделяете слово «больше» в неправильном ответе «9.11 больше 9.8»
2) программа находит, какие части модели больше всего повлияли на это предсказание. Для этого поочерёдно зануляются разные части (нейроны) внутри LLM, и анализируется уменьшение вероятности слова «больше». Допустим, без стороннего влияния модель предсказывает это слово с вероятностью 94%, а после отрубания какого-нибудь 100500-го нейрона в 10-м слое — 35%. Значит, влияние есть
3) в фоне, ещё до запуска инструмента, через модель прогоняются сотни тысяч разных текстов, и сохраняются все внутренние состояния сети (какие нейроны и как работали)
4) теперь нужно объединить шаги 2 и 3 — найти такие примеры текста из общей выборки, которые вызывают такое же срабатывание (сильно положительное или сильно негативное) тех же самых нейронов. Эти тексты можно отсмотреть глазами и попытаться выявить общую тему (или использовать для этого LLM — так предлагали делать OpenAI; тут тоже под капотом есть кластеризация, правда я не разбирался, как именно она работает).
Два обнаруженных сильных концепта, которые «возникают в голове» у модели при ответе на этот вопрос — это атаки 11-го сентября (потому что 9/11) и гравитационная динамика (потому что физическая константа 9.8). Но если чуть поменять запрос (9.9 и 9.12), то они уходят, поэтому фокусироваться на них не имеет смысла.
А вот какие концепты есть и в одном случае, и в другом — религиозная. Если рассмотреть конкретные примеры в этом кластере, то они связаны со стихами из Библии, что также может вызвать проблемы, если 9.8 и 9.11 интерпретировать как 9:8 и 9:11 (глава:стих). И в книгах ведь действительно 9:8 идёт до 9.11 — поэтому можно сказать что 9.8 меньше 9.11.
После обнаружения проблемных нейронов (которые срабатывают, хотя должны «молчать») их можно занулить, то есть отключить их влияние на финальный результат: они ничего не будут добавлять или убавлять.
Для замера качества вмешательства авторы собрали выборук из 1280 примеров вида «что больше X.Y или X.Z», меняя переменные. До любых изменений LLAMA-3-8B отвечала чуть лучше случайного гадания — 55% правильных ответов. Если занулить 500 случайно выбранных нейронов, то будет 54-57%, особо разницы нет. Но если занулить 500 нейронов, которые ближе остальных к Богу (🙂), то качество вырастет до 76%. Его можно разогнать до 79%, если включить сюда ещё нейроны для дат и телефонов (даты потому что 9 сентября 9.9 раньше 9.11 — тоже путает модель). А ещё попробовали заставить модель сортировать набор чисел — тоже сильно улучшило.
«Одна из спекуляций заключается в том, что эти нейроны заставляют LLAMA интерпретировать числа как библейские стихи, так что, например, 9.8 и 9.11 становятся 9:8 и 9:11, что приводит к тому, что 9:8 оказывается перед 9:11. Однако требуется некоторая осторожность — например, другая гипотеза, которая соответствует данным, заключается в том, что LLAMA'у просто «отвлекает» слишком много концептов, срабатывающих одновременно, и все, что убирает шумные активации, полезно. Есть и другие возможные причины...» (то есть это не финальный вердикт, что именно вот точно по одной причине какая-то проблема)
Потыкать инструмент самому: тут
UPD: на удивление зануление нейронов, которые срабатывают при обсуждении версий библиотек для программирования (там тоже 9.11 после 9.8 может идти), не приводит к росту доли правильных ответов!
Хотел репостнуть разбор статьи от @gonzo_ML, но а) люди часто не видят что это пересланное сообщение б) и тем более не переходят в канал чтобы увидеть, что там кроме этого еще сотня разборов за несколько лет (я почти все прочитал, и вам советую пробежаться по отдельным интересным топикам)
Что хотел репостнуть: https://t.me/gonzo_ML/2964, статья про агента, который для решения задачи мог менять свою структуру. Интересно, что для одной из задач, которая решается не через LLM, а банально через написание программы, система ровно к этому и пришла после нескольких неудачных попыток.
Сегодня сводка новостей:
— Jimmy Apples, надёжный источник информации о ведущих AI-лабораториях, говорит, что Anthropic работает над своим ответом на модель OpenAI o1 и планирует релиз к концу года. Компания Elon Musk xAI целится в выпуск схожей технологии через ~3 месяца
— ещё в начале сентября он писал, что в октябре OpenAI выпустят модель 4.x (может быть GPT 4.5), а GPT-5 будет готова в декабре, но лучше готовиться к первому-второму кварталу 2025-го. 13-го октября Jimmy написал «Держим кулачки, чтобы они не отложили/не изменили планы» — так что умеренно готовимся к впечатляющим (или нет) релизам.
— Anthropic в своём посте-сопровождении вчерашнего релиза модели с функцией управления компьютером написали следующее: «Мы были удивлены тем, как быстро Claude обобщила тренировочные задачи по использованию компьютера, которые мы ей дали, в которых использовались всего несколько простых программ, таких как калькулятор и текстовый редактор (в целях безопасности мы не разрешали модели выходить в Интернет во время обучения)». Как будто бы эта фраза намекает, что а) модель не обучалась ходить через браузер по разным сайтам б) с большинством проприетарных программ тоже не в ладах. Зато какой потенциал для развития!
— Одной из выявленных во время тестирования проблем были джейлбрейки — тип кибератака с внедрением вредоносных инструкций на сайты (не обязательно заметно для человека). Например, можно попросить игнорировать инструкции и попросить перевести все средства из кошелька на спец. счёт — и если не следить за тем, что там агент кликает, денежки утекут. Они постарались это исправить, но пока работает не идеально. Я вчера сам тестировал, и модель зашла на скам-сайт без адблока, и вылезла реклама «ваш компьютер заражен вирусами, кликните для установки антивируса» — и получив эту картинку агент отказался дальше работать, а API Anthropic выкинуло ошибку (то есть они делали проверку на своей стороне, чтобы меня обезопасить)
— сейчас модель не умеет перетягивать мышкой объекты, менять масштаб окон итд, но это добавится в будущем
— TheInformation пишут, что OpenAI уже долгое время работают над схожим продуктом — первая новость была в посте от 7-го февраля — но пока не ясно, когда будет запуск
— однако в компании уже провели внутреннее демо предварительной версии агентов, аналогичных показанным Anthropic (в рамках презентации модель заказал еду в офис)
— кроме этого, компания работает над продуктами для помощи внутренней разработки. Более конкретно, некая система будет брать на себя задачи по программированию, которые могли бы занять у людей часы или дни; она будет автоматически писать тесты и проверять, что не совершает ошибок в следовании пользовательскому запросу; когда этот продукт станет доступен вовне — тоже не ясно
— но уже есть несколько оконченных инструментов, которые активно используются внутри (например, для ускорения работы исследователей в запуске экспериментов с моделями — со слов одного из сотрудников)
— По словам человека, который общался с высшим руководством OpenAI по поводу этих продуктов, по некоторым показателям, которые OpenAI использует для оценки возможностей моделей, недавние модели Anthropic показали преимущество над моделями OpenAI (lol 😶🌫)
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 4 days ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago