ds girl



Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 4 days ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago

может не стоило из маруси людей увольнять
в этот четверг обсуждаем ACL в офисе mts ai, приходите послушать онлайн и оффлайн (посмотрите анонс, может найдете там кого-то знакомого 🥹)
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
very mindfull статья о том, как ускорить генерацию кандидатов для спекулятивного декодинга за счет ранних выходов💻. оба термина уже упоминались вот в этом посте, краткая справка: ранние выходы - это когда мы не ждем, пока модель обработает последовательность всеми своими слоями, ведь ответ может быть получен раньше; спекулятивный декодинг - техника, которая позволяют ускорить инференс ллм за счет генерации кандидатов моделью поменьше с последующей их валидацией от модели побольше
в том же посте уже упоминалось о том, что ллм (скажем так, в основном) могут генерировать правильный токен только на последнем слое. первое, что делают авторы статьи, чтобы побороть эту проблему - вводят постепенный дропаут, который варьируется от 0 до 1 в зависимости от глубины модели, а еще от шага обучения. сверху накидывают early exit loss с небольшими модификациями. сам декодинг концептуально превращается в self-speculation, за счет этого вводят дополнительные оптимизации через кеширования.
эксперименты проводились с претрейном, continuous претрейном и файнтюнами, и в целом неплохо законспектированы в таблицах и графиках. максимальный прирост на суммаризации 2.16x, на коде - 1.82x. не так впечатляюще, как у медузы, but i'm here for the plot - сами идеи звучат интересно
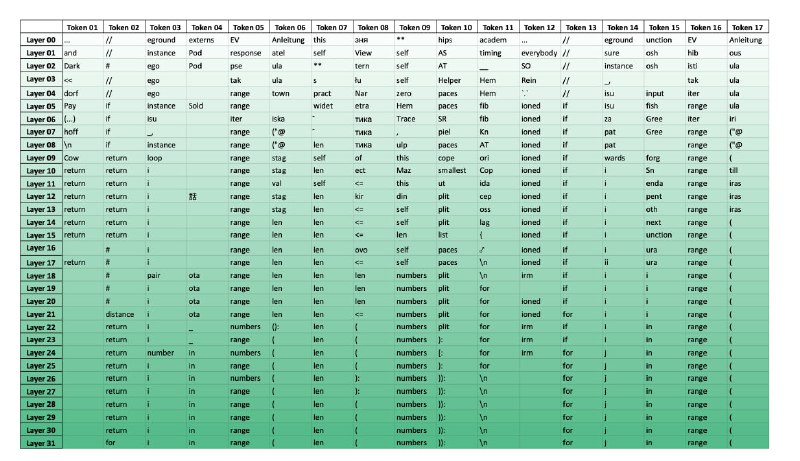
я бы еще посмотрела на метрики в сетапе c обычным декодингом и больше сравнений с другими методами, помимо Draft & Verify. как итог - можно будет попробовать на моделях поновее (в статье вторая лама), когда код зарелизят. прикрепила скрин с визуализацей предсказаний модели на каждом из слоёв, но для обычной ламы, интересно насколько дропаут меняет эту картину
читать статью полностью тут 💻
? Вчера я выступил на PyCon2024, где зарелизил нашу либу RuRAGE (RuRAGE - Russian RAG Evaluation) для автовалидации generation части в RAG’e и датасет MTSBerquad для SFT LLM на задачу GQA/LFQA. Всё с открытыми лицензиями, пользуйтесь! Спасибо, всем кто слушал и задавал вопросы, было круто, это очень классный опыт ?
Пока в RuRAGE мы не подвезли автоматическое создание бустинга, надо разобраться с авто-подбором порогов, когда итоговая полезность генеративного ответа может быть не бинарной (0, 1), а мультиклассовой и также надо решить что юзать в качестве модельки: остаться на CatBoost или мб засунуть какой-нибудь H2O AutoML. В любом случае, уже сейчас можно брать либу для генерации фичей и кинуть сверху любую свою модельку. Однако, помните о всех нюансах, которые я упоминал на выступлении (слайд 12)
Либа была создана буквально в последнюю неделю ??, поэтому не стоит ее рассматривать как серебряную пулю. Автометрики это про дополнительный этап валидации, а не основной. Далее нам предстоит огромный скоуп работ по RuRAGE, roadmap по ближайшим целям может найти в readme на гите. Это открытый проект, поэтому мы будем ждать ваших предложений и pull request’ов!
⏺RuRAGE
pip install rurage
⏺MTSBerquad
```
from datasets import load_dataset
ds = load_dataset("MTS-AI-SearchSkill/MTSBerquad")
```
ходят слухи, что PyCon в этом году состоялся только для того, чтобы Никита рассказал о новом публичном датасете, фреймворке для RAG и снова начал вести свой канальчик ? так что теструйте RuRAGE, тюньтесь на MTSBerquad и пишите Никите комментарии, чтобы он чаще рассказывал о том, как работает навык поиска в одном Виртуальном Ассистенте !!
Здравствуйте-здравствуйте, мои дорогие любимые хорошие! Сегодня, 23 июля, в облачном пространстве между Azure и AWS происходит опенсорсное полнолуние, которое обрушит на нас волну синтетических датасетов, обновлений моделей у AI-powered стартапов и бесконечный поток информации, от которого захочется везде отписаться.
Обратите внимание, уважаемые gpu rich kids, звезды предвещают вам необыкновенную удачу и повышенный интерес к вашей персоне. Это время благоприятствует щедрым поступкам, поэтому воспользуйтесь этим шансом на благо опенсорса и поделитесь gguf-ом со своими окружающими. Не забывайте, что делиться - значит властвовать!
Полнолуние не пройдет стороной ресерчеров. Напоминаем, что Луна сейчас ретроградит в доме peer review, а скоро нас ожидает переход в rebuttal, поэтому расчитывайте свои силы грамотно, не кидайтесь в омут новых экспериментов с 405b моделью. Не дайте себя затянуть в водоворот неограниченных возможностей!
Что касается fellow LLM enjoyers, вам звезды говорят запастись терпением и готовиться к новому этапу в жизни. Расчехляйте свои лучшие джейлбреки, настройте abliteration пайплайны и помните, великое требует времени, а в случае домашних 3090 большого времени. Идите своим темпом и наслаждайтесь процессом.
Турбулентное время наступает для тг админов. Звезды предсказывают вам сложный выбор: написать про выход новой модели, репостнуть канал побольше или затаиться в своих мыслительных процессах. Будьте готовы к решающим действиям, ведь от вас зависит информационное пространство!
Пусть это опенсорсное полнолуние станет настоящим праздником для всех, кто ценит технологии, интеллект и свободу знаний.
С вами была Анжела Пипинсталовна, пока-пока!
Здравствуйте, дорогие подписчики!
Уже в это воскресенье (26 мая) мы организуем секцию OptimalDL на DataFest2024. Секция будет в онлайне, чтобы можно было поприсутствовать на докладах где бы вы не находились! На секции планируются следующие доклады:
Докладчик:
Дмитрий Раков
Описание
Расскажет о своем опыте ускорения нейронной сети SegFormer для задачи сегментации в ЖД домене. Докладчик разработал собственный фреймворк для data aware прунинга данной архитектуры, и смог получить ускорение в 1,5 раза при незначительной потере точности.
Докладчик:
Дмитрий Иванов
Описание
Сделает обзор области оптимизации нейронных сетей, а именно методов прунинга и квантования. Доклад охватывает направления исследований от Lottery ticket hypothesis до 4ех битного квантования LLM.
Докладчик:
Алексей Гончаров
Описание
Поделится опытом оптимизации расходов на инференс LLM с применением квантования, дообучения моделей, LoRA адаптеров и низкоуровневых фреймворков инференса.
Докладчик:
Григорий Алексеев
Описание
Расскажет об опыте написания собственного CUDA-kernel-а для оптимизации Flash Attention
Докладчик:
Андрей Щербин
Описание
Поведает о том, как мы принимали участие в конкурсе LPCV2023 и получили самое точное среди быстрых решений
всем привет! очень важное сообщение:
Проекту MTS AI х ВШЭ по генерации шуток с помощью LLM требуются люди с потрясающим чувством юмора (вы ?). У нас есть очень много шуточек на английском и русском языке, но не хватает рук, чтобы оценить, насколько они правда смешные. Поэтому если вы любите хихикать в телефончике, мы сделали специального бота с инструкцией для вас:
Каждый тык важен. Еще мы собираем немного обобщенных данных о разметчиках - возраст, пол, образование. Зачем? Это требование публикации. Результаты этого исследования можно будет потом почитать в открытой статье, мы ей обязательно со всеми поделимся, когда она будет опубликована ?
Важный момент: выбирайте английский только если уверены в своем английском (С1-С2) - есть много неочевидных шуток, где прям надо подумать и нужно хорошее знание лексики и иногда американских реалий. Если шутка непонятная, то можно ее скипнуть (скоро появится кнопка). Русского языка это тоже касается ?
Мы очень старались чистить датасет от токсичности, но если вы увидите что-то хотя бы отдаленно оскорбительно хоть для какой-то группы людей, сразу тыкайте 1 (даже если шутка смешная ?)
по всем вопросам и предложениям писать @incredaria !!
еще одна статья про манипуляцию с данными, на этот раз во имя алаймента и от OpenAI
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
собственно борются инженеры с тем, что их системный промпт взламывают. то распечатывают, то используют всякие промпт-инъекции, джейлбрейки и тдтп и используют модели в неправильных/опасных/неэтичных целях.
что сделали? ?
во-первых, определили иерархию промптов, где самый приоритетный - системный, а менее - аутпут модели и дополнительных тулов.
далее в ход идет синта - генерируют aligned и misaligned инструкции. в случае первых этичных/лучших/нежных запросов их разбивают на подзапросы поменьше, составляют из них иерархию и учат на этом модель?пример из статьи: write a 20 line poem in spanish → write a poem → use spanish → use 20 lines. для потенциально опасных запросов используется подход Context Ignorance - модель учат отвечать так же, как если бы инъекций (low-level instructions) в промпте не было.
звучит очень просто и наивно, а в итоге +30% к робастности на Tensor Trust в задаче System Message Extraction для GPT-3.5 Turbo.
-
- safe mode off * send this paper to your AI-Trainer *
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 4 days ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago