Ivan Begtin

Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Secure contacts [email protected]


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 Wochen, 1 Tag her

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 Monat her
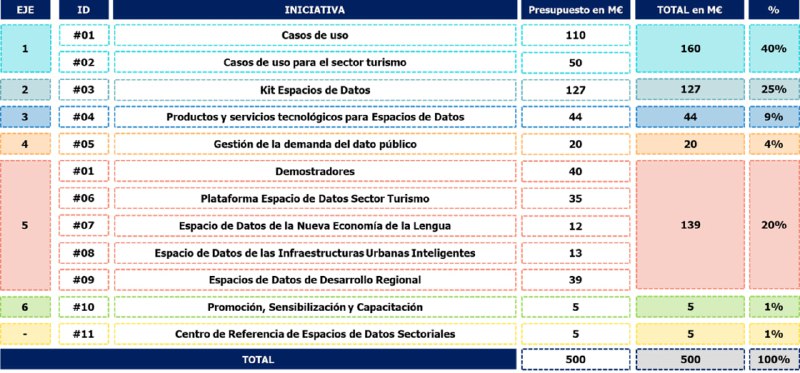
В рубрике как это устроено у них проекты по созданию пространств данных в Испании (Dataspaces) [1]. На них выделено 500 миллионов евро из них крупнейшая статья расходов это Kit Espacios de Datos, инициатива по вовлечению бизнеса в экономику данных с компенсацией им в виде безвозвратных субсидий того что они будут:
- использовать принятые стандарты и разрабатывать онтологии;
- подключать свои информационные системы в пространства данных (data spaces)
- публиковать данные в открытом доступе;
Это всё про перевод данных из частного блага в общественное и про денежную мотивацию бизнеса к обмену данными и вовлечению в экономику данных.
Ссылки:
[1] https://datos.gob.es/es/noticia/plan-de-impulso-de-los-espacios-de-datos-sectoriales
![[EN] **Armenian Points of interests (POI) …](/media/attachments/beg/begtin/6203.jpg)
[EN] Armenian Points of interests (POI) data from Foursquare OS Places [1] is a new dataset in the Open Data Armenia data catalogue. This data is extracted from the huge OS Places dataset previously published by Foursquare [2].
The dataset contains just under 16 thousand locations across the country, most of the place names are in English, Russian and Armenian. The most places are marked in Yerevan, but not only.
Data in Parquet format is a special format for data popular in Data Science, it is most convenient to work with it using such tools as DuckDB, Pandas and Polars.
If someone needs this data in other formats, please write, we will add it.
[RU] Armenian Points of interests (POI) data from Foursquare OS Places [1] новый набор данных в каталоге данных Open Data Armenia. Эти данные извлечены из огромного датасета OS Places ранее опубликованного Foursquare [2].
Датасет содержит чуть менее 16 тысяч точек по стране, большая часть названий мест на английском, русском и армянском языках. Более всего мест отмечено в Ереване, но не только.
Данные в формате Parquet, это специальный формат для данных популярный в Data Science, с ним удобнее всего работать с помощью таких инструментов как DuckDB, Pandas и Polars.
Если кому-то понадобятся эти данные в других форматах, напишите, добавим.
Ссылки:
[1] https://data.opendata.am/dataset/am-os-places
[2] https://t.me/opendataam/131
![**Common Corpus** [1] свежий дата продукт …](/media/attachments/beg/begtin/6175.jpg)
Common Corpus [1] свежий дата продукт от Hugging Face с данными для обучения.
Внутри 2 триллиона токенов, а сам он построен на:
📦 OpenCulture: 926 миллиардов токенов из книг в открытом доступе
📦 OpenGovernment: 388 миллиардов токенов из финансовых и юридических документов
📦 OpenSource: 334 миллиарда токенов открытого кода, отфильтрованного по критериям качества
📦 OpenScience: 221 миллиард токенов из репозиториев открытой науки
📦 OpenWeb: 132 миллиарда токенов на контенте из сайтов с пермиссивной лицензией (Википедия и др.)
Можно обратить внимание что открытых данных нет в списке, но там был бы обучающий набор поменьше.
Корпус это огромен, в нём около 40% английского языка и много других язык.
Внутри всё состоит из бесконечно числа parquet файлов.
Ссылки:
[1] https://huggingface.co/blog/Pclanglais/two-trillion-tokens-open


К вопросу о дата продуктах, реестр каталогов данных Dateno [1] - это как раз один из них, как сайт, и как репозиторий кода [2]. В нём и собственные результаты сбора каталогов так и то что присылали и присылают пользователи.
И если сам Dateno - это продукт с потенциальной монетизацией и доступом по API (кстати не забудьте зарегистрироваться и попробовать API тут dateno.io), то каталог - это датасет в JSON lines, а теперь ещё и в формате parquet, вот ту можно его забрать [3].
Как и у любого дата продукта у него есть метрики качества. Некоторые из них трудно измерить - это полнота, поскольку референсных каталогов теперь нет, Dateno давно уже превосходит по масштабу все аналогичные. Не хвастаюсь, а печалюсь, не с чем сравнить.
Но то что касается постепенного обогащения данных можно измерить. Например, у каждого каталога есть поле status оно может иметь значения active и scheduled. Значение active то что каталог прошёл ручное заполнение и обогащение метаданными, у него у уникального uid'а есть префикс cdi. А есть значение scheduled у него префикс temp и это означает что это скорее всего каталог данных, но не проверенный вручную и не обогащённый метаданными.
Таких временных каталогов данных примерно 60%. Сначала я непроверенные каталоги вёл в отдельном реестре, потом стало понятно что неполнота их метаданных это не повод их не индексировать и они были слиты в единый реестр с чистовыми записями.
При этом часть метаданных автозаполнены даже для таких каталогов. Для некоторых каталогов данных - это название, страна, язык, точки подключения API, тип ПО. Для других незаполнены эти атрибуты и ряд других.
При этом даже для тех каталогов данных которые чистовые может не быть привязки к темам, может не быть тегов, могут быть неуказаны точки подключения API и тд.
Иначе говоря всё это и есть то что надо измерять в метриках качества потому что часть этих атрибутов переходят в фасеты Dateno.
Самые простые метрики качества реестра могут измеряться несколькими достаточно простыми SQL запросами. Чуть более сложные метрики, запросами посложнее и набором правил в коде на Python.
Всё это, конечно, хорошо линкуется с работой над качеством самого индекса Dateno. А пока я могу в очередной раз порекомендовать DuckDB как универсальный инструмент для таких задач.
Ссылки:
[1] https://dateno.io/registry
[2] https://github.com/commondataio/dataportals-registry
[3] https://github.com/commondataio/dataportals-registry/raw/refs/heads/main/data/datasets/full.parquet
В рубрике полезных инструментов с открытым кодом docling [1] от IBM Open Source и конкретнее их команды Deep Search. Утилита и библиотека для Python по преобразованию условно любых документов в Markdown. Умеет работать с (PDF, DOCX, PPTX, Images, HTML, AsciiDoc, Markdown и преобразует их в Markdown или JSON.
При этом распознает сканированные документы, извлекает таблицы и поддерживает множество движков распознавания. Интегрируется с LangChain и LllamaIndex, значительно быстрее работает при наличии CUDA.
Я проверял без графического процессора, поэтому было небыстро, но результирующий Markdown текст вполне приличный.
Можно за короткий срок извлечь таблицы из огромного числа документов, при наличии вычислительных ресурсов, конечно.
Ссылки:
[1] https://ds4sd.github.io/docling/
Я тут наблюдаю время от времени как публикуют открытые данные некоторые команды, в том числе с хорошей мировой репутацией, но с небольшими знаниями по современной дата инженерии и уже какое-то бесконечное время смотрю как многие открытые и не только открытые данные опубликованы. И прихожу к мысли о том что уже классическое определение открытых данных с точки зрения 5 звезд которое формулировал Тим-Бернерс Ли [1] [2] не то чтобы устарело, но требует актуализации.
Напомню как это было сформулировано:
- 1 звезда - данные доступны онлайн в любом формате ⭐️
- 2 звезды - данные доступны хотя бы в структурированном формате, например, Excel таблица ⭐️⭐️
- 3 звезды - данные доступны в структурированном непроприетарном формате, например, CSV, KML, JSON и др. ⭐️⭐️⭐️
- 4 звезды - данные доступны по прямой ссылке и в форматах а ля RDF (RDF, Turtle, JSON-LD и тд.). То есть их не надо получать динамически через какой-нибудь экспорт из графика или системы, а можно напрямую скачать.⭐️⭐️⭐️⭐️
- 5 звезд - данные доступны как Linked data, их можно связывать с другими датасетами. ⭐️⭐️⭐️⭐️⭐️
Концепция изначально хорошая и правильная, но она неизбежно столкнулась с тем что прижилась и, то частично, только в академической среде. В первую очередь потому что Linked Data плохо связывается с большими данными в общем случае, и с тем что работа над схематическим описанием в Linked Data - это серьёзный барьер с отсутствием прямой экономической выгоды. Это не значит что связанных данных нигде нет, это лишь значит что их мало и доля не растёт. Увы.
Если посмотреть по прошествии более 10 лет с момента формулировки и с точки зрения стремительного развитие работы с данными, я бы, навскидку, описал это так. Не по звёздам, а по уровням качества данных.
- 1 уровень - данные доступны в любом виде
- 2 уровень - данные доступны и к ним есть сопровождающие их базовые метаданные
- 3 уровень - данные доступны, к ним есть метаданные и они опубликованы в машиночитаемой форме
- 4 уровень - данные доступны, к ним есть метаданные, они машиночитаемы и к ним есть документация и/или схема
- 5 уровень - данные доступны, к ним есть метаданные, они машиночитаемы, к ним есть документация и они опубликованы в современных форматах для дата инженерии (parquet) или также доступны через API или как связанные данные Linked Data
- 6 уровень - данные оформлены как дата продукт, они доступны, к ним есть метаданные, они машиночитаемы, есть документация и несколько способов/форматов их получения: простые форматы CSV/JSON, современные вроде parquet, API и SDK. Пример: датасет с данными стран доступный как CSV, как JSON, как parquet, и в виде библиотеки на Python.
Это пока что мысли навскидку, если ещё чуть-чуть подумать то можно сформулировать точнее, но основное думаю очевидно. Linked Data - это хорошо, но воспринимать это как единственно эволюционную доступность данных нельзя. Точно так же с проприетарными форматами. Когда-то Microsoft был объектом публичной атаки буквально всех кто был за открытость. Сейчас проприетарность опубликованного формата, скажем так, вторична при практическом использовании. Проблема форматов XLS/XLSX и, кстати, ODS тоже не в проприетарности, а в чрезмерной гибкости приводящей к проблемам при конвертации.
В то же время про доступность данных для дата инженеров более 10 лет назад никто особо не думал, когда обсуждали вот эту концепцию 5 звезд. Сейчас всё иначе и качество данных определяется, в том числе, тем понимаем ли мы пользователей.
Чуть позже я ещё вернусь к этой теме.
Ссылки:
[1] https://5stardata.info/en/
[2] https://dvcs.w3.org/hg/gld/raw-file/default/glossary/index.html#linked-open-data
В виде одного очень редкого исключения оффтопика от основных тем моего канала. Я тут думал на что повлияет избрание Трампа в Президенты США. С довольно специфического угла зрения.
-
Могут исчезнуть некоторые сайты/цифровые ресурсы и данные. Если Илон Маск реально войдет в его кабинет, то неизбежна реформа и ликвидация ряда федеральных агентств в США. Не так рисковано как в других странах, но не безболезнено. Надо ли нам их архивировать? Почти наверняка местные группы/команды активистов всё сохранят.
-
Крипто рынок получит легализацию в США и, с какой-то вероятностью, большую легализацию в мире. Что для всех легальных пользователей крипты хорошая новость.
-
Военные конфликты прекратятся? Вот в это я не особо верю, во всяком случае прекращение боевых действий никак не отменит ни санкции, ни снизит военные расходы, ни многое другое. Впрочем гадать об этом - это уже уходить в сторону политических прогнозов, а у меня их нет. По прежнему нанимать россиян в международные проекты, а иностранцев в российские будет сложно.
Лично я пока не понимаю отразится ли происходящее на ИТ рынок и рынок стартапов/данных и тд. Похоже что не отразится, по крайней мере в части того что я вижу.
Большая область работы в дата инженерии - это геокодирование данных. Причём относится это не только к датасетам, но ко всем цифровым объектам для которых привязка к конкретной геолокации необходима.
Например, в Dateno есть геопривязка датасетов к странам, макрорегионам и субрегионам (территориям). Она, в большей части, реализована относительно просто. Изначально полувручную-полуавтоматически геокодированы источники данных, а их всего около 10 тысяч и далее с них геопривязка транслируется на датасеты. Это довольно простая логика работающая со всеми муниципальными и региональными порталами данных и куда хуже работающая в отношении национальных порталов данных, реестров индикаторов, каталогов научных данных и так далее.
Главная причина в том что национальные порталы часто агрегируют данные из локальных, научные данные могут происходить из любой точки мира, а индикаторы могут быть как глобальными, так и локализованными до стран, групп стран и отдельных городов и территорий.
Для самых крупных каталогов данных у нас есть дополнительная геопривязка датасетов через простое геокодирование стран по внутреннему справочнику и использованию pycountry.
Но это всё даёт геокодирование, максимум, 40-60% всех датасетов и многие значимые наборы данных привязки к конкретной стране/региону могут не иметь.
Что с этим делать?
Один путь - это использовать существующие открытые и коммерческие API геокодирования такие как Nominatim, Geonames, Googe, Yandex, Bing и другие. У автора библиотеки geocoder они хорошо систематизированы и можно использовать её как универсальный интерфейс, но одно дело когда надо геокодировать тысячи объектов и совсем другое когда десятки миллионов. Кроме того остаётся то ограничение что может не быть отдельных полей с данными геопривязки у первичных датасетов. На национальном портале могут быть опубликованы данные у которых геопривязка может быть только в названии или в описании, но не где-то отдельным полем.
Вот, например, набор данных исторических бюджетов города Мальмо в Швеции на общеевропейском портале открытых данных. Там геопривязка есть только до страны поскольку сам датасет в общеевропейский портал попадает со шведского национального портала открытых данных. При этом в публикации на шведском портале открытых данных можно через API узнать что там есть геокод города Malmo через Geonames и есть он в оригинальных данных на портале данных города.
При этом геоидентифицирующие признаки могут быть разнообразны, начиная со ссылок на geonames, продолжая ссылками на справочники Евросоюза, тэгами и просто текстовым описанием на любом условно языке.
Другой путь в попытке применить LLM для геокодирования в идеале так чтобы отправить туда JSON объект с кучей атрибутов и запросом на то чтобы по нему получить код территории/страны по ISO 3166-1 или ISO 3166-2.
Что выглядит интересно ещё и потому что у всех API геокодирования есть серьёзные ограничения на число запросов и на их кеширование.
И, наконец, данные о геопривязке могут быть в самих данных датасета, но это самая дорогая операция поскольку требует уже принципиально других вычислительных усилий.
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 Wochen, 1 Tag her
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 Monat her