Рекомендательная [RecSys Channel]
![Рекомендательная [RecSys Channel]](data:image/webp;base64,UklGRswQAABXRUJQVlA4IMAQAADwSgCdASqgAKAAPulepk2pJSOiMjYtMSAdCWxne1HMOS8Pvv57ypOS++ySL+y7j/vPK8+A75Xo28ozpBebHzn/Ot36LepP8JjbUrJs+5V3DPmNyh2szR4iHKP+92TU8j/w+Wb9o367XHJDrD3lcM1VeCA57EYHVTdQYk4ihYvzViTCXJ9DI+3bSa8D3pb3kY9P7fCqUzYsj7vEosO1ewWN8uk8cJvLlMUjUJ+lKbW9qYsKdIR03S1PoZF+Jn+LLv6xEL1z5nttwTxVgGF5LsWHvVR9RyZhEddwfuhE+ReyG20qDLwRJ0FYGb0+EdSJvXTu/0/70yhRkA6FHvhPpFL5XoyALUqabKqNfmcxBo66UjobOHFBhOm9WeK1qpMcyzvay8627ppaoIq04vulIT8ucsuNGccEngi/3aWoOU3gjjSF89jLJpIZ98okkm3OxEiVvysDwxBnh7+m8srsbpnbf4pkPYv/Hqrzzw24QTbk+UeWtVYM/+O7dJ/NjctvOZCvPwNJyRI5f+Ab3zoMccaeWGZxT2En63hYkNLrb9ZH945JZEJqXUQpSuFda9tdyiUkTeH9/4qq6HGqXJ4duqDWqp39hbFsXkdIdtt3sCCAlp8J4Rt6wR6jyxE5IiseH0SmuSA86kZ9LCMjY4CqD+5bpTDQXKj1IwNxoMYfOv6E1NWkRdY4pdK9TGSLqOmM/7/Es1NMJLvnAiZiGvvcbKQGm1ik+9Ez+jzgFujdb4kA0cwCdrg/cf5AnOcdiI7G5CKjgLd1Ijs6p7iC+qehZth+TGK2UMmifcQNzT7hUNxOAAD++1tTJyKlYW++9tAGb8AGUHKlV71ny9p6yOOvNikzo7i7a657JLHhVQKbN/hFKsjLgl8gtmGdOcMSws8mHph4b03HuzoA7LJBRdA5RmTt2EJTRJVATi7PNh+XyknnHvqE+FiVF8WQLF6gFaIAuBGAvKVMES6C6H+0RafKhcKDdAcE0eLcvcP/smyQUDmVfnSyhXJcYMj0Pj973JmWWgIC4Q6B20SThYokSpt0ApW7/Lnsg6bLoS5fQ/gji3r894kTd+IZh1jhxbhUubJxt8y2fEAe4ORbWxBm19CuJnS/4+k/yvkFydiulsaze9nho4pAfHwTQvkzWNQXQqOi2+qfGlDOeZUHx715LW2meOqU9x7vrCVUbMIr8tR5uU1/xSy0xdISTBpaOdr8eh3m4zbHqUnodEMLGCPZOpN8mxZvxxcAKrsCL2t2Q/cS2Pkx/tW+2zZAW2t/IQu9rCgw6h64j9PVM4PD2kET5gp45K6gIFi6obLT3QGpP+Ef67diYpx/YFIoqli77Oq8BYy02I/8lmTKh5Hta1azeiDHiT60db8a0eGvX5sUXCCppq4TxpGLgRetqfWzPDz+VUFMWBGYawVV/hPf3S5+nILQrCS06lG2em0+67FGB875Ct64cp3O4vsZz6doxB6vEdSfbHPJuejLBZWKtEze2+Hqo805bilNxUN/2icuorL7D9LNF5C240FdHeDpMqyqY8ucuLLIHxr0vB1zBXkqBSzG1tKTzEL8+ER3rR5AQ1U3o2GdXZtVNSh+FfX43jMZV3HDw4jRAW7LVxuMcgpCi8Y5upAWhGaqyCCWjj7xR1Tggh3YAtELLq6GsfCQGnm0O5UrxD8vcVh1CZMIAtYn+Kiyw8BnlTJC3O02eGnFcMePPJWn/Rsh3bGKKB3FkvC1nyEXTt5mF5RVtgcnd2kN37Cg//lT92MjTQEsYdyrWdsz4ThN0iMpY7+BOrXwuVRTgDxnJleY4v7j3Q38om5FKW1/6Uuvl8+7o9aWrVJ1y6i7cCZ2R4Q+cvWn8pHhRGYV5C8r8apusnfCHJnkL5SiOISfBkdg1n99EcgNyyswDrdbqDfo4qX0x2DmYJQtKTugYvrIW3LfNJi4LTmjSMLqUVBsf5hYxIIbbgRJqCB0E6uk3OwH5UZ+7P/CcOo+nM6arXXwRDTgNwvzTjI6h2tb1quF7dUKMz5IMOFQ9EmNkQ6BoTIHAIf9eS5lIdxhO8/M16T93FwxtGxaIwYBT2M/eMWv1RwbEi4GYrZSQjb5/dl+0PAi/3n80rdf4Uh7SMYcTxQIeizZpn1kLv9XCgiTp/oMZrpK9yB4eisD85PrF+vvcXDu+FSbW0zo/D4jWOOKF24XorUhayFeMq3+CpZmPR4OTkhgta7BZEUrGhYoPGtJcRwwWwf7lKTk2kfpepoScPWlLy+cgcfMuaZZkI02C88gaYsdzm4LLaUiem04TlDKTvj8YwzLkcbjl15UwoKZrHkrVASVQvA3HMReTGuq61GPofidQ1UxvN2+H/XhGtMFsIfoXQkD28Ws+3EWAb4gAWihHlWkf6HB6vv5/kr8HMeuzj7Hr2/voTJYaxbSqhW1Keot0FMCEEYD7tvrv3uztsCyLVXJwQerKEDZLzcz3sKICyCeJiJQZ3pWekFjRYTQZjRd29/YRAJ9PBpgY6GdxBz6y4jDTFpbTVKVh9V9popDWJ1lbDabbXVkKM0eynck8j676unZ7R/afEHUBDZI67TWGZRAF3BcaPmefFb9uWbdAOqL/bc9B1MHfWqqCpRVBLchglZBTqd12ZDzB9hGHsouuN52B1RiEGSTTmdaL0j/jbjO42tJLYNj7PL5jOdBqFUWBHy5BDJ6vozLfag12Ft/a+9Rfcjdp2/ugvzcn3mrhT5QeGZ4be+LpC2IDiAPg5l2pISowp/XBitAvepuJy0xLdfygxRxF6zyvJRuHh0k3CLcb5IMlp0RW3RIScHBd3UKFGaruVOvcOX7P6v/+qJMX8p61FDrcea01vuoYHQTnqZ2kQmyAmd9kpB/lnDuaQm9l7P3M2k0o5oyG9yRV6YK4xjWi7rVwKuCx4Po1R53UJ2jm5MxhGJL7J5pCHKzMS/t8xlRA55+MMjeaWc60n4kb4c5e518DI904ZtiryoFl5E0sjhLipcvUVlIWGRlYL8Vjpa0ZY3OylJgQ/09lYmvQOkpCZMXO49wod8ocetdetwqJp2S/B2DNUaEQJ0vh7raXG39Arirh6uhoa+pBVXJJ4IT1syqp0ky6nDHPzz/4XnPdljDz1aCL/x7kkNyw0PteVE6VtMwcFVGUDwQoeTh3nZVsEcanVAl3XHb+7NkO5AzoLhcDgMw854jBXaLs3Fkpz7xuejK5eUspN6G0TVIcVl6kSeFGRuVRpUZLsKUUTOlK0qjHtiUXcgRqiZSzlq7U/O8V/Y7e4J0cAQ4nLZIzPPmxD8xdl4aYan8TeI73GMrdRSdqZ8sEGt22QYmYjO9z8w5yPrsJsQB8JldFCSdJ/TtwTFuUOoHGDpwjX/SqKc3IcWTj8qpaTu7WYHC7DTJtdgGrtn1lIEn305vfRvBfq/aLHk/QZ1RWHemQbwvoGyEis5sfFgoKSgpNDxP0lG4EFlhlOzIefdAwKXPekRAyHdYXYzYyajrIcoGY1R3kWM+6jdV9jRFSym9oCZAaAHfzkQbVdrCOVOxBw0iQM+PZodTZFRqAL/jP1ZUGe9N8v5P6jMyv1wMfEK5BUrk4tSsJCrLyHfpq6Prhhgt9NuILzGF1nO+16D/aJng0tTCoPlgkMvtpM8wLseBHyDb8GfytHhkweK/VK4ZzgKN9SgCTqMrSXazmyeZYv/1rOJznYyhZpqWsCxoe2uRQGgtO3rPMJ822/CWQbsMrWVyKchygKmSeK1Afv1hWd1J8feWBt5bplucYMT6ng12cT5v5viPBL+N30jJssMybBVDCc+oxhFn6c6o6B6srQIGqdLn17zwuuY67zAhmO4uGM0Lo2BqDfEDDsnoklQ3LUiH9gqJo5T04kvrD7KC0vsH1y+E5iFU0bKKYfoOVar3Q1wBiJYdpPys9ZV1X1ATB30+IWJr+wD1sRdLNfzRAM4d6nTWg8hUkjTVSlopiTP3IHjkB3ZyFat4mukwCc2+qyb6nOu9QdDB16+OFhQ47Ms3oA0L4Hb7MChMmM0drp5OL/oRJh+63oqi/en+EXaRm3FSsWt0RAe8DM6L7Ac0HBMHzOkeojWHv9dRUQO8Dfywp8OujVo1yJYUCGhuuwvFOD1xeDqsi2WZJFjkWmo9fyh04IzJMpbtE2ZElZBjxmUZae1dzOW2RqPMlrkbMGy9VQ94fNA1nhKEG+546EfIGG6dc2/Jc5ggwLijEIK2/kI1V/5UmucMfYAT3Yr9oxzRMcUXDxCJV6zbR1XZQk7v9qdkpZJ89G+TBQKBfLX8YnCTkiJ4yZgzo4wMu/BqUXWQu7D3er4vJTq+S03uBWKcZaXZwY1sidM9jcYmlwq0tZyFtBlsBdRTLzhXM1ikeBEQ5zAbyJW4dG/DECHpWFK/zJylnhTS/haNpXFkH7YbkhT7iEK2+W5kUK71XSr57XzMb44UKFVyPbdkt+Y5/H2dez8OXoPtPBfKvHZLAArOwm3y0opcTQdSxUiShp1oZZQJBRyXgJu7ZwQaPGWFDT+xouXRxuwqYsM1LWpueAqUYTCYiByozEPppuoQRc3kG1WsaAho3OpYDA39UtzVYcT+qC5pWFKMiGBsUK4+lBV42/IC5NpdssKlykrTz2CdRUhvl0prTD0u+UF4f6RKZDJP2qvfk8JQQKmTitP/StWBThahIug/7Lxka3PO7mGcllSFy88otB4IMMtUqsYDOv2fCJy5lwupuEnczpQ+bdkd5e5SFIXzHbOhw6LzEXSu+Li3DuZ3hWprrQAM/DBpep7/aqNE2FvGL8is4olqcId8fUeEF+RaPAtXjYl29KL++NgkHz2XQGJu6Qoq2sZbqZ9RG6YOofpBR90nsrXG5LFme4m+ebnFCtZIThFOkabqHFML8BILTG7Lq+NKHoU67cdx/2rvwjyA1hdYmbisrN1cAwfkvkmtudNUTrcuuiMzzRcObPIozlF8EOsBEv6mREQMfWCpfZRoajfJZ8AAxh/cs/Qr9L2YZd+utw0R9d96NhxjXH9VktqrtPa1EDLj4xJc8nxA+90KEAe4eqqTs8E5pw06pyz247SYGjAX32/1It88G35iDwpPpJP4CxSdy/s3oH86Y/IqrY9JEKKt6RWeRUYQm6uQjFd+nznG7LaqxyzYMDEX74x32x/WyIMS8AjwfPgogotNobaPN8VmFAv/uVINhj32Odj6siPk0iHAtFOgyyB++ljcGMSrZpFx8mJybOdsowWyBF2VuGiqwMuqd7r4YeQ6+Ov8FHzR7ecFgyROQKSgt6MAmLno1/KY2T6+KfbgeG8qoN+8QJLB+MbmhTEkbbG+wRVls6p9CIWJwjHTYadPXdbbbJRea1kuIGSMafKKRgL2xA6gbcE9rR86JePLNCXIuaa43A6Z4GKdqrOlwEMH/uJmwm+f0NTkU3E9uZCeEh1wPJZsWLznLMgk3DffdwQG88W3ThC+5kzYq9200EVyszwJ3DzeTFyfGqvkAA430WcURZ64VkP1F2W0QF3EcwsasWHQtFnclqUURlT3dzI6KoXPu0IUmkR9R1lZoE9ski8g3WNUP2gfAS1jsjYcQsTzbdq/jucb8oDCCrlKQwAgyuDoJP7MkWDPk92T7pQ04pbuoOluPiaqD2Ri1WY18vLbYtEL2dZR5KCHujQ/kyCJxmBosBaGGMTV5s6mZ1Rronn7SevV+o3COMD6y49tosXr79b95PXXbLo4gxQ0Mb1J8B+7Paj3hLiOuTm44/WBmbjQHgAA)
Вопросы и предложения > @yandex_ml_brand


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 1 month ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 2 weeks ago
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
часть 2
Далее в статье описываются нюансы реализации. Авторы рассматривают:
- Два возможных подхода к дистилляции:
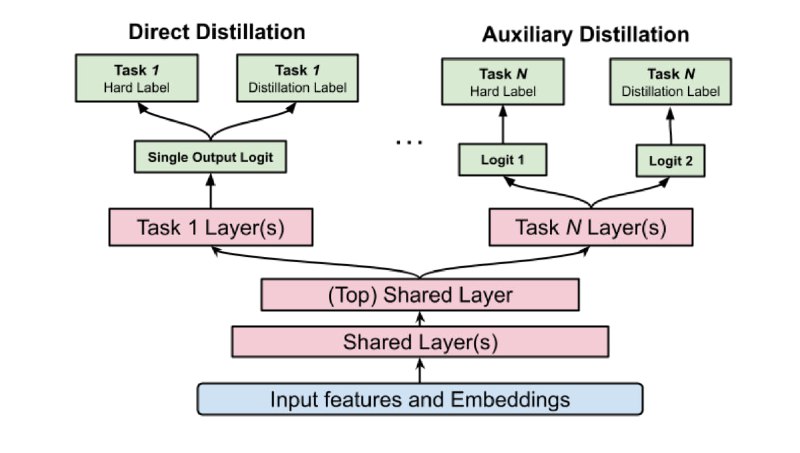
🔹 Direct distillation — дистилляционный и основной лосс применяются к одному логиту в модели-ученике.
🔹 Auxiliary distillation — в модели-ученике есть два раздельных логита: для основного и для дистилляционного лосса. Схема показана на иллюстрации.
Второй вариант хорошо себя показал для задач предсказания LTV: в офлайн-замере RMSE он на 0,4% лучше direct-подхода. Это объясняется тем, что LTV — очень шумный и плохо откалиброванный таргет: большая модель выучивает биасы в данных и остаётся плохо откалиброванной. А потом передаёт свои биасы ученикам и приводит к зашумлению таргета. Поэтому лучше использовать два отдельных логита.
-
Какие таргеты стоит использовать для дистилляции. Все таргеты можно поделить на 3 группы: Engagement (например, клики), Satisfaction (лайки или досмотры) и остальные. Авторы отмечают, что лучше использовать только Engagement и Satisfaction — это даёт прирост +1,13% Satisfaction +0,39% Engagement относительно модели без дистилляции. Добавление дополнительных таргетов влияет на общие слои и ухудшает итоговые результаты.
-
Как комбинировать ученика и учителя. Архитектуры ученика и учителя похожи, главное отличие — глубина и ширина внутренних слоёв. Авторы провели онлайн-эксперименты для комбинаций, когда учитель больше ученика в 2 и в 4 раза: в 2 раза больший учитель позволил добиться прироста +0,42% Engagement и +0,34% Satisfaction относительно модели без дистилляции, в 4 раза больший учитель — +0,85% и +0,80% соответственно. Но эффект масштабирования не будет продолжаться бесконечно, а увеличивать учителя ещё сильнее сложно: во-первых, его нужно обучать на больших объёмах данных, за несколько месяцев. Во-вторых – поддерживать онлайн.
@RecSysChannel
Разбор подготовил ❣ Петр Зайдель
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
часть 1
Сегодняшнюю статью подготовила для RecSys 2024 команда Google. В ней они рассказали, как используют дистилляцию для ранжирования видео на главной YouTube: не шортсов, а именно роликов на главной странице.
Говоря о дистилляции в CV или NLP, обычно подразумевают классический пайплайн:
🔹 обучение большой модели на некотором объёме данных;
🔹 подготовка датасета из предсказаний большой модели;
🔹 обучение маленьких моделей с использованием предсказаний большой нейросети.
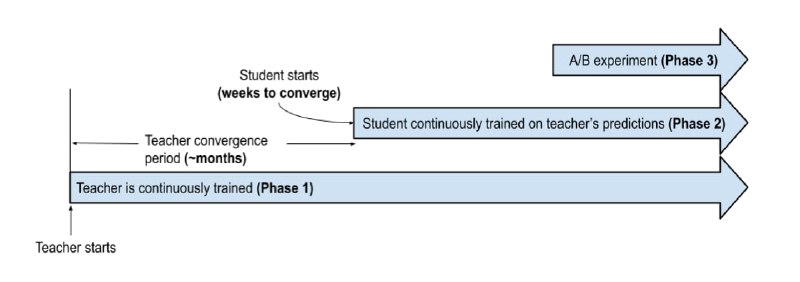
Применять такой подход напрямую для рекомендаций не получится: поведение пользователей, набор рекомендуемых айтемов меняются со временем, иногда даже в течение дня. Это значит, что один раз обучить большую модель на длинном промежутке времени и использовать её как учителя не получится, она быстро устареет. Для точных рекомендаций YouTube учитывает в дистилляции distribution shift: постоянно дообучает модели нейросетевого ранжирования на свежих данных.
Как это устроено — показано на первой схеме. Большая модель-учитель непрерывно обучается на данных за период порядка месяцев. Каждая порция таких предсказаний записывается в таблицу, и маленькие модели-ученики используют их в процессе дообучения.
Для большей эффективности используется только одна большая модель-учитель, заточенная на несколько задач сразу. Маленькие же модели готовятся для более узких целей, каждая для своей. Такой подход, ко всему прочему, позволяет быстрее и дешевле запускать эксперименты, поскольку для обучения учеников требуются недели, а не месяцы.
@RecSysChannel
Разбор подготовил ❣ Петр Зайдель
KuaiFormer: Transformer-Based Retrieval at Kuaishou
Сегодня разбираем свежую работу от Kuaishou о том, как они используют в реалтайме трансформеры для кандидатогенерации.
Kuaishou — суперпопулярный в Китае аналог TikTok: 400 млн активных пользователей, 600+ тыс RPS. В среднем один пользователь просматривает сотни видео в день.
Это первое внедрение в Kuaishou трансформера для кандидатогенерации. По их словам, — самое успешное внедрение за последние полгода.
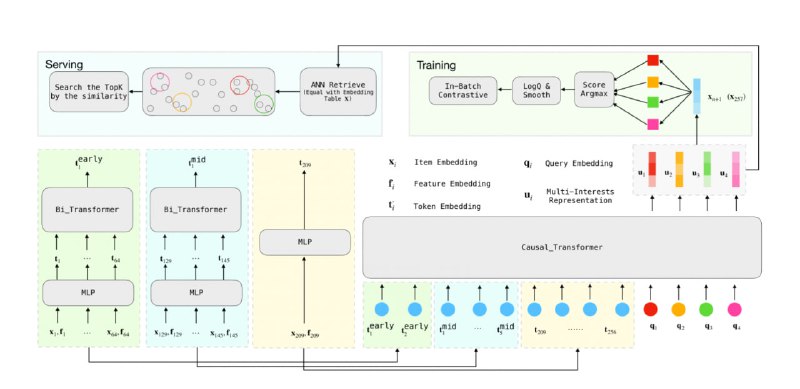
Новая модель получила название KuaiFormer. Опираясь на историю взаимодействия пользователя с продуктом, она помогает предсказывать следующие положительные взаимодействия (в случае Kuaishou — это, например, лайк, полный просмотр видео и т. д.).
PinnerFormer, SASRec, Bert4Rec и другие похожие работы плохо улавливают разнообразные интересы пользователей, поскольку представляют их в виде одного вектора. Подходы MIND и ComiRec решают эту проблему: они умеют выделять целые кластеры интересов — так рекомендации получаются более разнообразными. KuaiFormer объединяет в себе оба подхода — она умеет справляться с главными проблемами реальных рекомендательных систем:
-
За счёт применения logQ-коррекции эффективно работает с большим каталогом айтемов при обучении.
-
Порождает разнообразные рекомендации, поскольку выделяет не один вектор интересов, а несколько. Во время обучения вероятность целевого айтема моделируется через вектор интересов, наиболее близкий к нему.
-
Работает в реалтайме, но не требует большого объёма вычислительных ресурсов, несмотря на огромные RPS. Добиться этого помогает сворачивание последовательных кусков истории пользователя в один вектор с помощью bidirectional-трансформера: самые старые айтемы, которые были актуальны достаточно давно, сворачиваются в один вектор, а самые свежие — остаются нетронутыми. Схема того, как 256 токенов превращаются в 64, показана на рисунке.
@RecSysChannel
Разбор подготовил ❣ Артем Матвеев

Recommender Systems with Generative Retrieval
Современные модели для генерации кандидатов обычно строят так: обучают энкодеры (матричные разложения, трансформеры, модели dssm-like) для получения ембеддингов запроса (пользователя) и кандидата в одном пространстве. Далее по кандидатам строится ANN-индекс, в котором по ембеддингу запроса ищутся ближайшие по выбранной метрике кандидаты. Авторы предлагают отойти от такой схемы и научиться генерировать ID айтемов напрямую моделью, которую они обучают. Для этого предлагают использовать энкодер-декодер трансформенную модель на основе фреймворка T5X.
Остается вопрос, как закодировать айтемы для использования в трансформерной модели и как научиться напрямую предсказывать ID в декодере? Для этого предлагается использовать наработки из прошлой работы — Semantic IDs. Такие ID для описания айтемов обладают следующими свойствами:
— иерархичность — ID в начале отвечают за общие характеристики, а в конце — за более детальные;
— они позволяют описывать новые айтемы, решая проблему cold-start;
— при генерации можно использовать сэмплинг с температурой, что позволяет контролировать разнообразие.
В статье проводят эксперимент на датасете Amazon Product Reviews, состоящий из отзывов пользователей и описания товаров. Авторы используют три категории: Beauty, Sports and Outdoors и Toys and Games. Для валидации и тестирования используют схему leave-one-out, когда последний товар в истории каждого пользователя используется для тестирования, а предпоследний — для валидации. Такой подход много критиковали за возможные лики, но авторы используют его для сравнения с уже существующими результатами бейзлайнов.
Semantic IDs строили следующим образом: каждый товар описывался строкой из названия, цены, бренда и категории. Полученное предложение кодировали предобученной моделью Sentence-T5, получая эмбеддинг размерности 768. На этих ембеддингах обучали RQ-VAE с размерностями слоев 512, 256, 128, активацией ReLU и внутренним ембеддингом 32. Использовали три кодовые книги (codebooks) размером 256 ембеддингов. Для стабильности обучения их инициализировали центроидами кластеров k-means на первом батче. В результате каждый айтем описывает три ID, каждый из словаря размера 256. Для предотвращения коллизий добавляли еще один ID с порядковым номером.
Энкодер и декодер — трансформеры из четырёх слоев каждый с шестиголовым аттеншеном размерности 64, ReLU активацией, MLP на 1024 и размерностью входа 128. В словарь токенов добавили 1024 (256 × 4) токенов для кодбуков и 2000 токенов для пользователей. В итоге получилась модель на 13 миллионов параметров. Каждый пример в датасете выглядит так: hash(user_id) % 2000, , … -> . Во время инференса метод показывает значительный прирост качества (Recall@5, NDCG) по сравнению с бейзлайнами (SASRec, S3-Rec etc). При этом нужно учитывать, что у предложенной модели намного больше параметров, чем у остальных.
Авторы проводят ablation study для семантических ID — рассматривают варианты их замены на LSH и случайные ID. В обоих случаях semantic ID дает большой прирост и является важным компонентом подхода. Также проводится анализ возможности модели обобщаться на новые айтемы. Для этого из датасета выкидываются 5% товаров, а на инференсе задают отдельным гиперпараметром долю новых кандидатов в top-k (с совпадающими первыми тремя ID) и сравнивают свою модель с KNN.
Статья получилась во многом академичной, но она обращает внимание на важное направление, которое сейчас активно развивается. Похожий подход можно использовать для кодирования айтемов для LLM, чем, судя по разговорам на конференции, уже активно занимаются. Также можно отметить, что в статье не раскрывается часть важных вопросов: как добавлять новые айтемы и как переобучать RQ-VAE (в реальных сервисах часто меняется распределение контента), а также хотелось бы увидеть сравнение на более приближенных к реальным датасетах.
@RecSysChannel
Разбор подготовил ❣ Петр Зайдель
Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (UniCoRn)
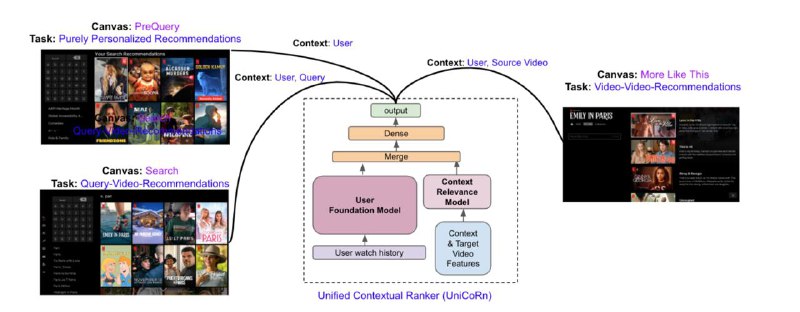
В ещё одном интересном докладе с ACM RecSys разработчики из Netflix делятся опытом объединения моделей для персонализированного поиска и рекомендаций. В статье есть несколько предпосылок. Во-первых, обслуживать одну модель в продакшене проще, чем несколько. Во-вторых, качество объединённых моделей может быть выше.
Представленная архитектура обучается на трёх задачах: персональные рекомендации, персонализированный поиск и рекомендации к текущему видео. Для этого в нейросетевой ранкер подаётся поисковой запрос, ID текущей сущности (видео), ID пользователя, страна и ID задачи, которая решается (поиск или одно из ранжирований). Также в ранкер подаётся эмбеддинг истории действий пользователя, полученный так называемой "User Foundation Model", детали которой не раскрываются ни в тезисах с конференции, ни в ответе на прямой вопрос после устного доклада.
Чтобы заполнить эмбеддинги сущностей, которые отсутствуют (например, поисковые запросы в задаче рекомендаций), авторы провели серию экспериментов, по итогам которых решили, что в задаче поиска лучше вместо контекста подставлять отдельное нулевое значение, а в задаче рекомендаций — использовать название текущего видео вместо строки запроса.
Авторы отметили, что до внедрения этого подхода на этапе, когда пользователь вводил несколько первых букв в поисковом запросе, показывались результаты, которые не соответствовали интересам пользователя, так как поиск не был полностью персонализированным. Сейчас проблему удалось решить. Также в докладе подтверждают, что логика отбора кандидатов для поиска и рекомендаций оказалась ожидаемо разной.
Результаты — рост на 7% в офлайн-качестве в поиске и на 10% — в рекомендациях. Это, по всей видимости, достигается за счёт регуляризации, возникающей при обучении на несколько задач и за счёт перехода к полной персонализации в поиске.
@RecSysChannel
Разбор подготовил ❣ Владимир Цепулин
![Рекомендательная [RecSys Channel]](/media/attachments/rec/recsyschannel/50.jpg)
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 1 month ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 2 weeks ago