Сергей Мелюков

Ведет @smelukov


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 6 days ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 1 week ago
Я покидаю Яндекс ??☺️
Это были хорошие 4 года: чему-то научился сам, чему-то научил других - было круто.
С благодарностью к коллегам за совместную работу ❤️
Сейчас у меня неделя отдыха, а после начинаю неистово работать над другим проектом, в другой компании ?
В результате недельного отдыха планирую значительно продвинуться с новой архитектурой статоскопа. За эти выходные набросал прототип, чтобы проверить накопившиеся идеи, полет отличный. Новая архитектура позволила избавиться от того, от чего давно хотел избавиться, упростить то, что давно хотел упростить, добавить фичи, которые давно хотел добавить… в общем, должно быть огонь!
Ну и, думаю, последний пост на тему css-парсинга в этом цикле )
Возможно, у вас в голове крутится что-то вроде:
"Сергей, в предыдущем посте ты плевался от работы с исходником через токены, а в генераторе сам этим грешишь!".
Все так, и в случае, когда нужно просто добавить пробелов - это ок. Более того, css-tree делает намного более детальную токенизацию, нежели postcss-value-parser
Но! Если все таки хочется заморочиться с контекстом и не вставлять пробелы только перед именем шрифта и только в свойстве font, то так тоже можно.
Решение делится на несколько этапов:
- найти все декларации у которых имя свойства равно font
- найти в них ноды со значением типа family-name
- вставить пробелы в генераторе только для этих нод
Этап 1: собираем все декларация типа font:
Для этого воспользуемся волкером и обойдем AST:
```
const {walk} = require('css-tree');
walk(compressedAST, {
enter(node) {
if (node.type === 'Declaration' && node.property === 'font') {
// нашли!
}
}
});
```
Этап 2: ищем в этих декларация ноды со значением типа family-name
Все не так просто. Так, например, здесь:
```
.foo {
color: red;
animation-name: blue;
}
```
только один цвет - red, а blue, хоть и валидное имя цвета, но используется как название анимации.
AST не знает какой тип значения (цвет, размер, имя шрифта и тп) хранится в ноде. Для этого, нам нужно подняться на уровень лексического разбора и найти нужные нам лексемы. Для этого у css-tree есть лексер. Вот его мы и используем чтобы в декларациях типа font найти все имена шрифтов:
```
const {walk, lexer} = require('css-tree');
const allFamilyNameNodes = new WeakSet();
walk(compressedAST, {
enter(node) {
if (node.type === 'Declaration' && node.property === 'font') {
const familyNames = lexer.findAllFragments(node, 'Type', 'family-name');
for (const item of familyNames) {
for (const node of item.nodes) {
targetNodes.add(node);
}
}
}
}
});
```
Теперь в allFamilyNameNodes хранятся все ноды, которые именно по смыслу содержат имя шрифта.
Этап 3: вставляем пробелы только перед собранными нодами
Здесь берем за основу уже знакомый нам код декоратора и чуть-чуть меняем его так, чтобы он срабатывал только для нод, которые мы собрали
```
const css = generate(compressedAST, {
decorator(handlers) {
return {
...handlers,
node(node) {
this.currentNode = node;
handlers.node(node);
},
tokenBefore(prev, current, value) {
if (
prev !== tokenTypes.WhiteSpace &&
current === tokenTypes.String &&
allFamilyNameNodes.has(this.currentNode)
) {
this.emit(' ');
return tokenTypes.WhiteSpace;
}
return handlers.tokenBefore(prev, current, value);
}
};
}
});
```
Всё.
Да, здесь можно было сразу найти все family\-name, не обходя декларация типа font:
```
const familyNames = lexer.findAllFragments(compressedAST, 'Type', 'family-name');
```
Но в таком случае мы бы нашли вообще все family\-name и в других свойствах. Тем не менее, вполне рабочий вариант, нечто среднее между первым и вторым, но мне захотелось показать более комплексный пример, да и такие вот комплексные штуки как раз используеются в разного рода плагинах к IDE, например.
Мой ПР, из поста выше, пока не посмотрели, а проблему решать как-то надо.
Начал перебирать варианты:
- заменить минификатор
- поменять csso и cssnano местами
- отключить у csso все оптимизации кроме вырезания неиспользуемых классов
Первый вариант слишком рискованный
Второй выглядит как так себе, потому что cssnano вышит в конфиг сборки, а csso просто используется в плагине, на этапе optimizeChunkAssets
Третий вариант тоже не подходит, потому что дело, как оказалось, не в csso, а в css-tree. Это css-tree убирает пробел:
```
const {parse, generate} = require("css-tree");
const ast = parse('.foo {font: 1em "Arial"}');
const source = generate(ast);
console.log(source); // .foo{font:1em"Arial"}
```
Делает это css-tree совершенно законно и генерит валидный CSS. У css-tree нет задачи восстановить CSS из AST в первозданном виде.
Но проблему, все такие надо как-то решать, например добавить пробелы перед строками везде, где их нет. Звучит как костыль, но пока мой ПР в cssnano не вмержили - ок.
Оказалось, что генератор в css-tree можно кастомизировать. Вот так можно вставить пробелы вообще перед всеми токенами:
```
const {parse, generate} = require("css-tree");
const {tokenTypes} = require("css-tree/tokenizer");
const ast = parse('.foo {font: 1em "Arial"}');
const source = generate(ast, {
decorator(handlers) {
return {
...handlers,
tokenBefore() {
this.emit(' ');
return tokenTypes.WhiteSpace;
}
}
}
});
console.log(source); // . foo { font : 1em "Arial" }
```
Хендлер tokenBefore используется для расстановки пробелов между токенами во время генерации из AST, потому что само AST не содержит информации о пробелах (whitespaces). Например, если парсить border: 1px solid red в AST и потом обратно в CSS, то именно tokenBefore даст понять генератору, что 1px, solid и red должны быть разделены пробелами.
Предыдущий результат - это, конечно, не то, что нам нужно, поэтому немного перепишем:
```
const {parse, generate} = require("css-tree");
const {tokenTypes} = require("css-tree/tokenizer");
const ast = parse('.foo {font: 1em "Arial"}');
const source = generate(ast, {
decorator(handlers) {
return {
...handlers,
tokenBefore(prev, current, value) {
if (prev !== tokenTypes.WhiteSpace && current === tokenTypes.String) {
this.emit(' ');
return tokenTypes.WhiteSpace;
}
return handlers.tokenBefore(prev, current, value);
}
}
}
});
console.log(source); // .foo{font:1em "Arial"}
```
Здесь мы добавляем пробелы только перед строковыми токенами и только в тех случаях, когда перед ними еще нет пробела.
Но мы же работаем не с css-tree напрямую, а с csso. Как здесь быть?
Очень просто. Если раньше мы делали так:
```
const CSSO = require('csso');
const compressedCSS = CSSO.minify(input.source, {
sourceMap: false,
restructure: false,
usage: {
classes: usedClasses
}
});
```
То теперь будет так:
```
const {parse, compress, generate} = require('csso/syntax');
const ast = parse(source);
const compressedAST = compress(ast, {
restructure: false,
usage: {
classes: usedClasses
}
}).ast;
const compressedCSS = generate(compressedAST, {
sourceMap: false,
decorator(handlers) {
// ...
}
});
```
Вот и всё, так я обхожу баг в cssnano
Теперь о том, как можно использовать revelation у себя, в качестве jest-резолвера:
rev-resolver.js:
const Revelation = require('revelation\-resolver').default;
const rev = new Revelation(options);
module.exports = (request, options) => rev.resolve(options.basedir, request);
jest.config.js:
module.exports = {
resolver: './path/to/rev\-resolver'
};
И всё.
Поделитесь пожалуйста своими циферками, если вдруг будете пробовать Rev у себя, очень интересно. Возможно, по сравнению с дефолтным jest-резолвером, такой разницы и не будет. Просто у нас нет большого количества чистых jest-тестов, чтобы провести корректный замер. А может, на вашем примере я пойму что еще можно улучшить в резолвере, чтобы он стал лучше и быстрее и так мы нанесем сокрушительную и непоправимую пользу другим ?
PS: нет, использовать Rev в качестве резолвера для webpack не получится, т.к. множество плагинов и внутрянка webpack завязаны на родной резолвер ?
А помните мой доклад про Testament - нашу внутреннюю разработку в Яндекс Маркете для интеграционных тестов на базе jest и IPC?
Так вот, все это время одной из самых бесячих проблем является скорость выполнения пака тестов (всего 7к тестов: 4к - десктоп и 3к - тач/мобильные устройства).
Мы много чего перекопали во внутренностях jest, многое о нем узнали, попробовали разные методики ускорения, от простых, до самых "упоротых" вроде форкнуть трансформер и научить его шарить кеш в CI.
Пока не будут рассказывать обо всех методиках, т.к. мы их сами еще только обкатываем, расскажу всего об одном, но очень эффективном. Сначала немного предыстории.
По результатам наших исследований, самыми медленными частями jest (не берем в расчет код внутри spec-файлов) являются: изоляция, трансформер, резолвер и сборщик кавереджа.
Вы можете возразить, мол, трансформер - это же про babel, какой смысл причислять его к внутренностям jest?
Да, но нет ?
У jest есть отдельный трансформер-фасад, а вот бэкендом может быть уже что угодно (babel, ts, swc, etc...). И вот этот фасад рулит кешем и всякими разными другими штуками и делает это не очень оптимально и это особенно заметно на больших паках тестов.
Резолвер - отдельная история. Подробнее смотрите в вышеупомянутом докладе. А если коротко, то jest-резолвер нам не подходит, т.к. мы собираем статику вебпаком и используем различные настройки webapack-резолвера. Поведение некоторых из них просто невозможно воспроизвести в jest-резолвере. Поэтому мы начали использовать родной резолвер вебпака.
Это замедлило нам тесты, потому что у webpack очень медленный резолвер и он активно работает с ФС, несмотря на встроенный кеш, а еще, он генерит очень большой callstack, но об этом позже. Мы решили выйти из положения при помощи memfs сэмулировав ФС в памяти и scanfs для сканирования реальной ФС и помещения структуры ФС в memfs. Таким образом, мы сделали нечто похожее на haste-map, который в jest-резолвере делает +- то же самое, и отыграли скорость, потерянную от переезда на enhanced-resolve.
Время шло, кодовая база росла, количество тестов росло, время прогона пака увеличивалось
Отдельно отмечу, что профайлинг такой конфигурации - занятие специфическое, потому что enhanced-resolve медленный и генерит оооооооочень глубокий стектрейс. Дамп прогона одного spec-файла часто достигал более 500мб и v8 просто отказывался мне его отдавать, потому что максимальная длина строки в v8 - 512мб. Да и дамп таких размеров - то еще удовольствие. А добавьте туда еще глубокую рутину внутри memfs, который тоже так себе написан и получите чудовищных размером cpu-профиль.
В какой-то момент я подумал, что "хватит это терпеть" и решил набросать собственный резолвер, который умел бы больше, чем jest-резолвер, но не был бы таким перегруженным и медленным, как enhanced-resolve. Так появился Revelation - быстрый резолвер модулей для node.js с поддержкой свойства mainFiles и возможностью модифицировать package.json налету. Резолвер обмазан всевозможными кешами, в том числе кешированием ближайшей node_modules (или другой директории с модулями, в зависимостями от опции). А со всеми этими приседаниями с кешем, memfs оказался уже не нужен, потому что revalation < enhanced\-resolve + memfs > enhanced\-resolve.
В итоге, мы получили следующее ускорение прогона тестов (основано на графиках нашего CI с 4к тестов в десктопе и 3к тестов в таче):
90 перцентиль:
- время уменьшилось на 55% в десктопе
- время уменьшилось на 40% в таче
95 перцентиль:
- время уменьшилось на 60% в десктопе
- время уменьшилось на 55% в таче
В качестве бонуса, получили возможность снимать cpu-профайлы и локально отлаживать большие тесты, потому что профиль похудел с более чем 500мб до 52мб (в 10 раз!).
Очень хороший профит как по скорости, так и по DX.
Из того, что еще хотелось бы реализовать - это поддержка свойств exports и imports в package.json.
Telegram
Сергей Мелюков
Привет! А вот и видео доклада. С тех пор мы придумали как ускорить jest, написав для нашей инсталляции кастомный рантайм, который делает меньше проверок на попытке зарекваирить файл. Казалось бы, проверки простейшие, но на тысячах рекваеров это сильно заметно.…
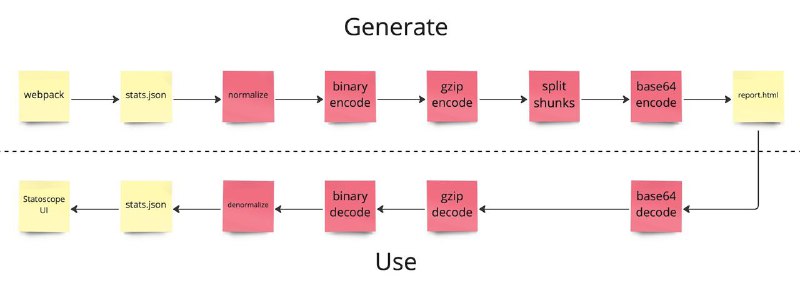
Идем дальше. На скриншоте изображен итоговый пайплайн работы со статами.
Чтобы получить HTML-отчет, статы проходят несколько стадий:
- нормализация (Да, статоскоп умеет нормализовывать статы. До нормализации, статы весят 1.5гб, а после - 250мб. Подробнее описывал здесь)
- сжатие с binary JSON
- сжатие с gzip
- пилим gzip-стрим на чанки (зачем это делать подбробно описывал тут)
- энкодинг чанков в base64 (чтобы можно было хранить чанки с бинарными данными в HTML)
- запись в файл
Всё, отчет готов.
Таков путь сырых статов в 1.5гб до HTML-отчета в 5мб (и это несмотря на то, что base64 дает оверхед в ~33% от размера декодируемых данных).
Когда мы открываем такой отчет в браузере, все происходит в отбратном порядке:
- декодируем чанки из base64
- разжимаем из gzip
- разжимаем binary JSON
- денормализуем статы
- отправляем статы в UI
Итого, самая медленная часть статоскопа - это денормализация статов и их подготовка к использованию в UI. А все потому, что webpack генерит статы, не особо заворачиваясь с форматом.
И тут мы плавно переходим к Statoscope 6, над которым я работаю уже довольно давно, с переменной активностью. Вот его основные фичи:
- собственный формат статов
- расширяемость как у vscode 😇
Зачем: чтобы любой человек мог написать плагин (если его еще нет), в котором реализован UI для его любимого сборщика. Сейчас же статоскоп сильно завязан на webpack и мне это не нравится.
Будет классно, если напишете какая у вас разница в размерах статов получилась, очень интересно.
PS: Я тут заглянул в OpenCollective статоскопа и выяснилось, что там уже 413$ накапало. Это конечно не webpack с миллионным бюджетом, но все равно приятно ☺️
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 6 days ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 1 week ago