TechSparks

Тем, кто больше любит слушать длинное чем читать короткое — могу посоветовать свой подкаст ;) http://sebrant.chat
Вопросы - @asebrant

Крупнейшее медиа об интернет-культуре и технологиях.
Больше интересного на https://exploit.media
Написать в редакцию: @exploitex_bot
Сотрудничество: @todaycast
№ 4912855311
Last updated 1 day, 6 hours ago

Не заходи без шапочки из фольги и пары надежных проксей. Интернет, уязвимости, полезные сервисы и IT-безопасность.
Связь с редакцией: @nankok
Сотрудничество: @holartem
№ 4958183748
Last updated 4 days, 4 hours ago

Первый верифицированный канал о технологиях и искусственном интеллекте.
Сотрудничество/Реклама: @alexostro1
Помощник: @Spiral_Yuri
Сотрудничаем с Tgpodbor_official
Last updated 2 months, 1 week ago

Китайская BYD — удивительная и вполне уникальная производственная компания. В мире известна как не просто основной — а уже вполне успешный — конкурент Теслы на рынке электромобилей: в 3 квартале этого года ее доходы от продаж электомобилей в 28 млрд долларов превысили показательТеслы (25 млрд).
Менее известный факт состоит в том, что BYD взаимодействует со знаменитыми американскими компаниями не только в режиме прямой конкуренции. С 2017 компания в секрете разрабатывала аккумуляторы для будущего автомобиля от Apple. iCar не случился, зато разработанная технология используется в машинах самой BYD.
С 2009 года компания входит в число поставщиков Apple, и в этом направлении занято 100 000 (!) сотрудников. Если начиналось сотрудничество с производства отдельных компонентов, то сейчас дошло до сложных сборочных операций. Сейчас BYD и титановые корпуса для последних моделей айфонов производит, и треть всех айпадов собирает.
И не собирается на этом останавливаться. Дженсен Хуанг делает большую ставку на роботов, и не только на процессоры для них. Совместный проект Nvidia и BYD направлен на производство роботов следующего поколения.
На этом фоне умиляют люди, периодически мне советующие поменьше писать и говорить про китайцев, которые, как они утверждают, только и умеют что красть настоящее и выпускать дешевые убогие копии.
https://www.benzinga.com/news/global/24/12/42260943/tesla-rival-byd-assembles-over-30-of-ipads-for-apple-and-plans-ai-robots-for-nvidia-how-warren-buffet

ChatGPT отмечает двухлетнюю годовщину. Читать интернет на эту тему прикольно. Кто-то иронизирует «уже два года прошло, а я еще не потерял свою работу», а кто-то как раз рассказывает, что ее потерял; кто-то причитает, что апокалипсис теперь совсем уже завтра, а другие рассказывают о начавшихся сбываться крутых ожиданиях. Одни восторгаются достигнутым, другие считают, что ИИ провалился в овраг разочарований на гартнеровской кривой и там и сгниет. Как всегда — реакция определяется верой и убеждениями: технофобы стенают, технофилы рукоплещут:)
Некий формальный и безэмоциональный анализ можно почитать в тексте от IBM (хотя, конечно, это позиция технологической компании, и потому скорее оптимистическая).
Основные пункты:
1. Демократизация ИИ. “Now people can leverage these tools without needing millions of dollars of investment. We will soon see one-person unicorns.”
2. Коллаборация людей и машин
3. Достигнута мультимодальность
4. Началось развертывание рассуждающих моделей
5. Прогресс в области малых моделей
6. Идут обсуждения пределов возможного для современных моделей, но плохо с метриками и вообще методами их оценок. “We don’t want AI to replicate humans; we want AI to be really good at what it does.”
7. Гонка инноваций, в которой не обязательно будет единственный победитель, хотя пока OpenAI похож на лидера.
С этой подборкой я скорее согласен:) И в любом случае — всяческие поздравления команде по случаю двухлетия малыша! или уже и не малыша…
https://www.ibm.com/think/news/chatgpt-turns-2.
Тем, кому этот оптимизм неприятен, можно посоветовать, например, посты в X от Gary Marcus, его прогноз таков:
Within 12 months, the GenAI bubble will have burst.
• The economics don’t work
• The current approach has reached a plateau
• There is no killer app
• Hallucinations remain
• Boneheaded errors remain
• Nobody has a moat
• People are starting to realize all of the above.

У меня сегодня в новостных лентах — сплошь КМУ в Сочи и выступления о важности для науки цифровых технологий вообще и ИИ в частности. На этом фоне контекстно выглядит интересный и глубокий (простите за невольный каламбур) манифест DeepMind о роли ИИ в науке. Там 30 с небольшим страниц, стоят того, чтоб всем интересующимся прочитать: и про возможности, и про суть, и про риски.
Основная идея: сегодня все науки, от генетики до метеорологии, сталкиваются с ростом масштабов и сложности во всей деятельности ученого, от работы с потоком литературы до сложнейших экспериментов, генерящих массу данных. Но именно с проблемами нарастания масштабов и сложности отлично работает глубокое ML.
Но внедрение ИИ-центричных подходов к научным исследованиям требует серьезной стратегии, а не попыток прикрутить ИИ любой ценой.
our essay can inform such a strategy. It is aimed at those who make and influence science policy, and funding decisions. We first identify 5 opportunities where there is a growing imperative to use AI in science and examine the primary ingredients needed to make breakthroughs in these areas. We then explore the most commonly-cited risks from using AI in science
Перечисленные пять возможностей:
1. Работа со знаниями
2. Работа с данными
3. Подготовка, моделирование и проведение сложных экспериментов
4. Построение моделей сложных систем и взаимодействий
5. Поиск новых решений в областях с очень большим пространством возможных решений (проблема синтеза белков тому примером)
Перечисленные пять рисков:
1. Не снизит ли ИИ креативность и новизну научных прорывов
2. Не пострадает ли надежность и воспроизводимость результатов, способность науки корректрировать собственные ошибки
3. Не заменят ли полезные работающие решения глубокое понимание их сути
4. Не затруднит ли ИИ доступ к науке представителям уязвимых групп
5. Не затормозит ли ИИ старания снизить углеродный след человечества
Как в начале прошлого века Гильберт сформулировал 23 проблемы, решение которых во многом определило математику XX века, так и сейчас ученым совместно со специалистами по ИИ предстоит определить направления, в которых использование ИИ важней всего.
Есть, правда, серьезная засада: scientific data is uncollected, partial, uncurated or inaccessible, making it unavailable to train AI modelsИ ее тоже придется решать, если мы хотим реально ускорить научный прогресс.

Ну наконец-то кто-то вслух высказался на тему бесконечных пузомерок из мира ИИ-моделей, называемых умным словом benchmarks, которые не только маркетологи в хвост и в гриву используют, но и более техничные ребята начали воспринимать всерьез — ну потому что как жить без пузомерки? Ленты новостей и каналы про ИИ завалены ежедневными сводками с полей разных арен и бенчмарков; мне вспоминаются времена, когда в еще некрупном Рунете было принято по утрам изучать счетчик Рамблера и делать из этого глубокомысленные выводы. Технологии изменились, людская (а разработчики тоже люди) психология — нет.
Так вот, группа исследователей решила разобраться с тем, что these benchmarks are poorly designed, the results hard to replicate, and the metrics they use are frequently arbitrary. Это становится уже серьезной проблемой, потому что за бенчмарки схватились и законодатели, которым же надо порегулировать на якобы объективной основе.
Авторы работы подтвердили и наличие, и серьезность проблемы и, как положено, предложили свои способы решения. Интересно, что из этого возьмет на вооружение сообщество. Есть у меня некий скепсис…
https://www.technologyreview.com/2024/11/26/1107346/the-way-we-measure-progress-in-ai-is-terrible/
Оригинал работы - https://arxiv.org/abs/2411.12990

А вот Nvidia продолжает демонстрировать, что компания не только про чипы, но и про собственные модели, иллюстрирующие красоту генеративного ИИ и крутость продуктов Nvidia — full version uses 2.5 billion parameters and was trained on a bank of Nviidia DGX systems packing 32 H100 Tensor Core GPUs 🙂
Модель по имени Fugatto (от Foundational Generative Audio Transformer Opus 1) описывается как a Swiss Army knife for sound, а сравнение ее с другими моделями звучит немножко токсично: some AI models can compose a song or modify a voice, none have the dexterity of the new offering 🙂
Музыкантам предлагается использовать новый инструмент на разных стадиях процесса — от прототипирования до улучшения качества имеющихся треков. Модель умеет создавать неожиданные эффекты: For instance, Fugatto can make a trumpet bark or a saxophone meow. Whatever users can describe, the model can create. Черрипики в приложенном треке звучат впечатляюще.
Осталось дождаться реакции и без того в последнее время нервных музыкантов:)
Поразительно, как не нравятся людям зеркала:) Вот вышла очередная тревожная работа команды гуманитарных исследователей из Германии и Великобритании.
Проанализировав сайты, созданные разными популярными генеративными моделями (ChatGPT, Claude 3.5, Gemini 1.5 Flash), они обнаружили, что дизайн содержит различные манипулятивные элементы, побуждающие пользователя к тем или иным действиям.
Вроде нет вопросов, откуда взялся такой стиль: модель училась на вполне человеческих творениях, которые все это добро содержат сплошь и рядом, и там элементы манипуляции были заложены в ТЗ заказчиками или отвечали собственному представлению вебдизайнеров о прекрасном.
Но исследователи волнуются, что модели демонстрируют не самое лучшее и бескорыстное поведение и требуют, как обычно, дополнительного регулирования и ограничений для моделей.
О каких-то ограничениях для людей вопрос даже не ставится. В итоге призыв выглядит как неуклюжая попытка сохранить коммуникационные функции за людьми: только белковым дано право манипулировать себе подобными:)
https://arxiv.org/pdf/2411.03108
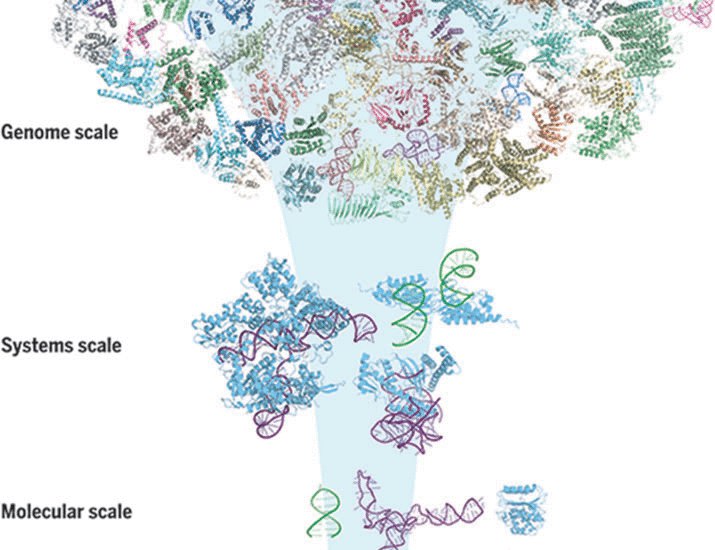
Foundation models стал популярным термином, все больше отраслей стремятся иметь свои модели, претендующие на фундаментальность. Логично, что появилась Evo, a multimodal artificial intelligence model that can interpret and generate genomic sequences at a vast scale… Evo represents a major advancement in our capacity to comprehend and engineer biology across multiple modalities and multiple scales of complexity
Впрочем, пока, хотя genomic foundation model enables prediction and generation tasks from the molecular to the genome scale — речь о геномах микробов. Насчет существ побольше, включая растения, животных и нас, пока неясно — удастся ли Evo усовершенствовать для работы с геномами такого размера. Но даже и с бактериями перед CRISPR открываются совсем новые перспективы
https://www.science.org/doi/10.1126/science.ado9336
Совсем популярный, но толковый пересказ:
https://singularityhub.com/2024/11/18/a-chatgpt-like-ai-can-now-design-entirely-new-genomes-from-scratch/

Еще 4 года назад тогда еще не запрещенная Meta объявила о проекте ARIA: исследованию будущего AR и VR очков. Больших откровений там не случилось, но анонс прототипа Orion вдохнул немного новой жизни. Теперь публике представлен Aria Research Kit: первые кейсы использования и призыв к сообществу делиться своими наработками.
Процитированные в тексте проекты трудно назвать новаторскими:
1. Картирование окружающего мира с помощью данных, собираемых носителем очков
2. Изучение звукового окружения пользователя, чтобы в дальнейшем помочь людям с потерей слуха не только лучше слышать, но и понимать пространственное расположение источника звука.
3. Улучшенный ассистент водителя, учитывающий события вне его текущего поля зрения
4. Улучшенная навигация в помещениях для пользователей с проблемами зрения
В новом раунде исследований компания предлагает раздать прототипы своих очков исследователям работающим над broad range of research topics, including embodied AI, contextualized AI, human-computer interaction (HCI), robotics, and more.
И ждет, конечно, их отчетов.
https://www.meta.com/en-gb/blog/quest/project-aria-research-kit-case-studies/
Вполне ожидаемо: появилась компания, всерьез сфокусированная на AI-оптимизиции. Собственно, с момента появления коммерческих интересов в интернете, возник и бизнес их обслуживания: как манипулировать трафиком на ресурсы клиента с разных информационных систем в интересах клиента. Но пока системы работали алгоритмически (начиная с Page rank), решения оптимизаторов были тоже алгоритмичными: “ах, он ссылки учитывает — наплодим ссылочные фермы” и т.п.
С ИИ-поиском не так все просто, поэтому неудивительно, что за дело взялась компания, изначально занимавшаяся управлением репутацией в сети, а не реинжинирингом поисковых алгоритмов: approach isn’t about hacking AI systems but rather systematically shaping the web content that feeds these systems.
Изучение изменений ответов ИИ на вопросы — вполне в духе хорошей аналитики: ответы на один и тот вопрос разнятся для разных пользователей, поэтому давайте эмулировать множество пользователей и смотреть, как изменения в интернете влияют на характеристики всей совокупности ответов. Учитывается два канала воздействия на ИИ: изменения в контенте, который используется для тренировки новых версий моделей, и изменения на страницах со свежей информацией, к которым модель обращается при подготовке ответа.
Интересно, получится ли такая же большая индустрия, как традиционное SEO. Первые стартапы уже есть.
https://crazystupidtech.com/archive/can-we-manipulate-ai-as-much-as-it-manipulates-us/
Крупнейшее медиа об интернет-культуре и технологиях.
Больше интересного на https://exploit.media
Написать в редакцию: @exploitex_bot
Сотрудничество: @todaycast
№ 4912855311
Last updated 1 day, 6 hours ago
Не заходи без шапочки из фольги и пары надежных проксей. Интернет, уязвимости, полезные сервисы и IT-безопасность.
Связь с редакцией: @nankok
Сотрудничество: @holartem
№ 4958183748
Last updated 4 days, 4 hours ago
Первый верифицированный канал о технологиях и искусственном интеллекте.
Сотрудничество/Реклама: @alexostro1
Помощник: @Spiral_Yuri
Сотрудничаем с Tgpodbor_official
Last updated 2 months, 1 week ago