Нейронный Кот

https://www.linkedin.com/in/fursovia


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 6 days ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 1 week ago
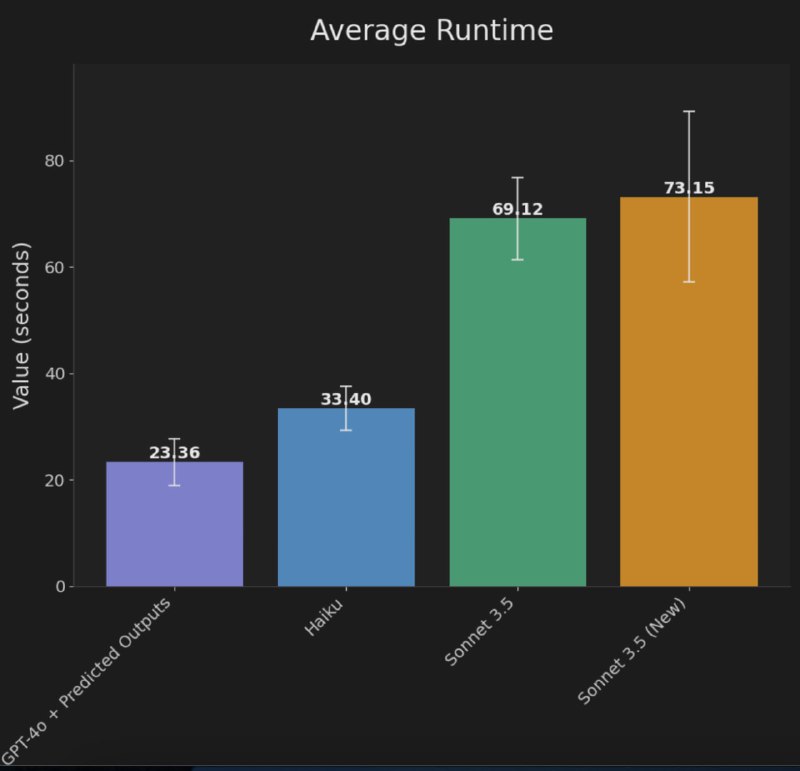
🤪 4x ускорение редактирования кода в gpt-4o
OpenAI релизнули новую фичу, которая ускоряет генерацию — Predicted Outputs
Для задач, где требуется редактирование ответа (например, кодинг), теперь можно передать новый параметрprediction в completions API.
Работает примерно так:
1. Мы показываем, какой ответ должен быть
2. Chatgpt одним форвард пассом понимает, где надо исправить ответ (или не одним, если исправлять надо в нескольких местах)
3. Исправляет ответ только там, где надо
Итого, тратится на ~порядок меньше форард пассов.
🔹Gpt-4o по скорости на таких задачах становится быстрее Haiku от антропика
🔹НО вас все равно чарджат за ваш "драфтовый" ответ по цене completion токенов
😠 Завтра все заходим в Cursor, выбираем gpt-4o, получаем ускорение в несколько раз
Почему в API sonnet 3.5 до сих пор нет structured outputs? 🔪 (это когда ты говоришь, какая JSON схема тебе нужна на выходе)
Они советуют заниматься какими-то дурацкими трюками, чтобы консистентность ответа повысить
- Очень сильно попросить в промпте, какая схема тебе нужна
- Добавить few-shot примеры
- Сделать prefill ответа ассистента (это ты первые токены json-а сам пишешь)
https://docs.anthropic.com/en/docs/test-and-evaluate/strengthen-guardrails/increase-consistency
SGLang — еще один фреймворк для сервинга LLM
Помните vLLM? Его выпустили люди, причастные к LMSYS Arena, 20 июня 2023 (чуть больше года назад!)
Тогда vLLM пришел на замену TGI от huggingface и принес PagedAttention, механизм, который эффективно работал с памятью для KV cache, что позволило увеличить throughput в несколько раз
С тех пор произошло несколько интересных моментов:
1. TGI поменял лицензию с Apache 2.0 на платную
2. vLLM стал более-менее стандартом индустрии
3. Появился новый игрок от NVIDIA — TensorRT-LLM с поддержкой FP8 и бэкендом для тритона
4. В TRT-LLM завезли KV cache reuse, который нам ускорил инференс на несколько десятков процентов
5. TGI вернули Apache 2.0 (pathetic ?)
В целом, во все фреймворки быстро завозили новые модели (мистраль, mixtral, phi, qwen, etc), новые фишки (cache reuse, fp8, speculative sampling, In-flight Sequence Batching, etc).
Эвристика для выбора движка была примерно такая:
? Хочешь быстро и просто — используй vLLM
? Хочешь очень быстро и сложно — используй TRT
Теперь у нас новый сервинг от LMSYS:
1️⃣ user-friendly
2️⃣ easily modifiable
3️⃣ top-tier performance
ТО ЕСТЬ ???
1. Запускать можно также просто, как и vLLM
2. Все легко можно настроить и захакать, потому что все на python и в опен-сорсе
3. По скорости также, как и TRT-LLM
Топ опенсорсных моделей для рол-плея ?
? gryphe/mythomax-l2-13b — модель на основе llama 2, проверенная временем. Ей уже почти год (!), а ей до сих пользуются на openrouter, и использование только растет (500M -> 2.5B токенов). И стоит всего $0.1 на вход и $0.1 на выход.
Когда в апреле вышла Llama 3, авторы модели выпустили ПЕСНЮ "Прощай МитоМакс", но моделька до сих пор жива
? openlynn/Llama-3-Soliloquy-8B-v1 — llama 3, обученная энтузиастами с реддита на 250М токенах ролплейных данных
? neversleep/llama-3-lumimaid-8b — llama 3, можно сказать, что наследник MythoMax, потому что в команде "обучателей" есть автор митомакса. Трейн сет состоит из 12 разных источников разговорных и не только данных
? Sao10K/L3-8B-Stheno-v3.2 — относительно новая trending моделька с хорошими отзывами на реддите
Где находить модели? На реддите SillyTavernAI, LocalLLaMA и Рейтинг openrouter
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 6 days ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 1 week ago