Старший Авгур




Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 2 weeks ago
 про Гутенберг, датасет пар …](/media/attachments/sen/senior_augur/294.jpg)
Помните историю про Гутенберг, датасет пар для обучения моделей писательству? Нашёлся-таки герой, который повторил его для русского, мой подписчик — Макс 👏
Вот сам датасет: https://huggingface.co/datasets/40umov/dostoevsky
Методология аналогична оригинальной. Напомню:
1) Берём книжки из общественного достояния.
2) Режем их на фрагменты.
3) Для каждого фрагмента автоматически генерируем промпт и выжимку.
4) Перегенерируем фрагменты языковой моделью.
5) Используем оригиналы как положительные примеры, а синтетические копии — как отрицательные.
Весь процесс был не особо автоматизированный, нарезка на фрагменты делалась вручную. Использованные книжки — на скриншоте.
Теперь дело за малым, нужно всего лишь обучить на этом модель 💪
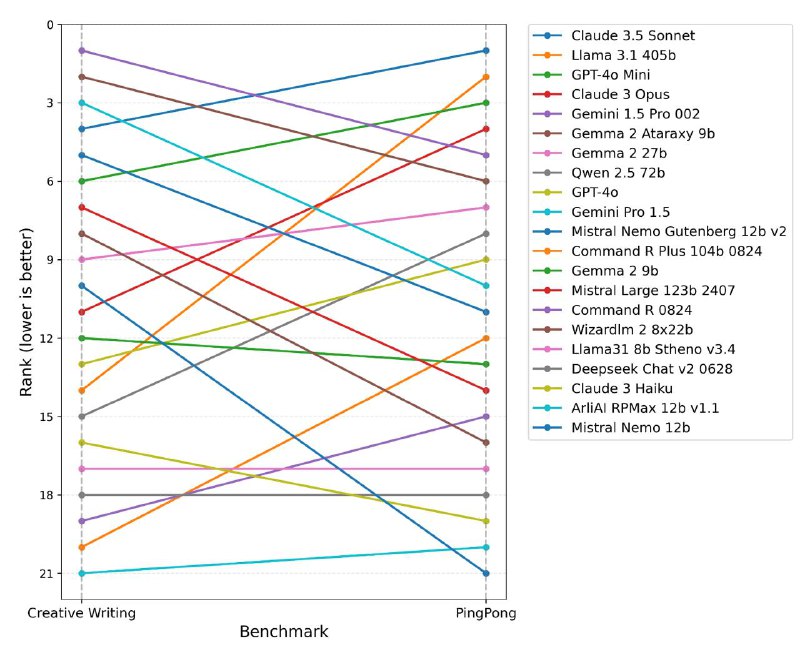
Долго ничего не писал, готовил ПингПонг к подаче на ICLR. Докинул циферок, поправил текст, сделал сравнение с Creative Writing. И наконец отправил, фух.
Ешё оказалось, что там теперь обязательно подаваться как рецензент для того, чтобы статью хотя бы допустили к ревью. Такую практику я в целом одобряю: любишь кататься, люби и саночки возить.
Так что я теперь возможно буду что-то там рецензировать.
Накрылась прокси, которую я использовал, чтобы отображать Claude в OpenAI-like API. Я уже сплю, поэтому пока убрал эти модели из бота, завтра починю.
UPD: всё работает
Про расширения RoPE
Первая часть: ссылка
Для начала коротко напомню, что вообще делает RoPE: берётся эмбеддинг и каждая пара фичей вращается на определённый угол. Для разных пар — разный угол. Для первого токена происходит один поворот, для второго — два поворота, и так далее. Вращаем и query, и key.
Кроме того, нас прежде всего интересует расширения контекст без дотюнивания.
Раздобыть данные на понимание длинного контекста и компьют на тюн не так уж просто.
Extending Context Window of Large Language Models via Positional Interpolation
Статья: ссылка
Казалось бы, ну и в чём проблема тогда? Пусть мы обучили модель на 4096 позициях. Тогда давайте просто вращать фичи 4097 раз, 4098 раза и так далее. Это называется экстраполяция ?, и экспериментально подвтерждено, что она не работает с популярными базовыми моделями. Причём подтверждено ещё много где. При этом со стороны теории это несколько загадочно: RoPE не обучается и кодирует относитетельную позицию, так какого чёрта? То есть ожидается, что после экстраполяции модель будет себя вести так, как будто у неё скользящее окно в 4к токенов. А на самом деле её полностью разносит, логиты внимания для некоторых расстояний >4к улетают в небеса. ?
Почему? Об этом чуть ниже.
Пока же сосредоточимся на втором семействе методов — интерполяции. Базовая идея такая: представим, что для токена на 4096 позиции мы делаем в 2 раза меньше оборотов, 2048. И так для каждой позиции, вместо одного оборота делаем половину. После этого мы можем кодировать 8192 токенов вместо 4096. Но есть нюанс: модель-то не видела в обучении полуоборотов, соседние токены становятся практически неразличимы ?
Поэтому авторы статьи полируют это всё тюном на расширенном контексте, что делает этот подход не особо практичным.
Scaling Laws of RoPE-based Extrapolation
Статья: ссылка
Суть статьи — обоснование провала экстраполяции. А виновата оказалсь база, θ = 10000 ?
Дело в том, что с такой базой не все фичи делают полный оборот за 4к. И в итоге для первых фичей модель видит полный оборот (и видит немонотонность функций), а для других фичей видит куски только до 2π, π или π/2. И как раз из-за наличия неполных кусков экстраполяция не работает как надо.
Авторы дотюнивают модель с разными базами, но в пределах оригинальной длины контекста, 4к. Если сделать базу радикально меньше, например 500, то все фичи совершают по несколько оборотов, и всё ок, экстраполяция будет работать с приемлемым качеством скользящего окна. С увеличением размера контекста становится хуже, но без переломов. Если сделать базу радикально больше, например 1000000, то точка перелома отодвигается на более широкий контекст, но всё ещё существует.
Хоть такой метод и выпадает из нашей изначальной постановки задачи, потому что снова надо тюнить, но тюнить-то надо на маленьком контексте ?, поэтому проблем со сбором данных тут нет. Работает всё неплохо, особенно с маленькой базой.
NTK-Aware scaling
Пост: ссылка
Меняем интерполяцию с дообучением из первой статьи на масштабирование базы θ без дообучения. Описано в посте на Реддите, хронологически до статьи выше. По идее это всё ещё интерполяция (особенно если задать коэффициент масштабирования с запасом), только мы растягиваем для разных частот по-разному.
Dynamic NTK scaling
Пост: ссылка
Добавляем изменение коэффициента масштабирования в зависимости от текущей длины последовательности. То есть если текущая длины меньше оригинальной — не делаем ничего. А дальше растим коэффициент линейно.
YaRN: Efficient Context Window Extension of Large Language Models
Статья: ссылка
Добавляются две новых штуки: NTK-by-parts и температура в софтмаксе внимания. NTK-by-parts мотивирован фактом выше о том, что какие-то фичи и частоты и так нормально экстраполируются, так что их можно не трогать. Для тех фичей, которые не экстраполируются, мы интерполируем. А температуру меняем, чтобы выравнять распредление скоров внимания (она меньше 1). Да и экспериментально так получается перплексия пониже ?
И вот YaRN уже работает как без тюна, так и с тюном.
Отдал ручки Сайги сюда: https://llmarena.ru/
Отдал v6, saiga_phi3_medium_sft_m1_d2_kto_m5_d7 и saiga_llama3_70b_sft_m1_d5_abliterated_awq_4bit
В боте доступны всё те же модельки.
По поводу бенчмарка я настроен скептично (не будет там много голосов), но пусть.
Опус и последний Соннет - единственные языковые модели общего названия, которые могут писать стихи. GPT-4o не вытягивает, а они - могут. Пример запроса: Пушкин про Warhammer 40k.
*В просторах звёздных, где царит война,
Где вечный мрак и пламя битв пылает,
Стоит Империум, как твердая стена,
И Император верных охраняет.
Десант в доспехах, грозен и могуч,
На кораблях несётся сквозь пространство.
В боях, где смерть разит, как черный луч,
Врагам несут лишь гибель и мытарство.
В соборах Марса, где гудят машины,
Свершается под гул молитв таи́нство,
Где люди-киборги среди руин старинных
Куют оружие, даруя нам единство.
Повсюду Хаос сеет смерть и тлен,
Рой ксеносов клубится в бездне чёрной,
Но человечество, восстав с колен,
Бросает вызов участи позорной.
О, сколько павших душ, несчётных жертв войны!
Но долг велит идти вперёд без страха.
И в этом мраке беспросветной тьмы
Лишь вера движет нас из праха.
Пусть дух Владыки нас ведёт на бой,
Пусть враг падёт пред нашею рукой!
Империум стоит, незыблем строй,
И мы верны присяге вековой.*
Местами криво, не с первой попытки, но с этим точно можно работать.
Короче, ситуация такая. В том случае, когда мы не учим lm_head и embed_tokens, шаблон важен. Особенно, когда спец. токены нормально не обучены (как в случае базовой модели). И в целом с 4 битами, Лорой и 8-битным оптимизатором 24 Гб памяти на градиенты обеих матриц хватает. Но матрицы в идеале должны быть в float32, чтобы модель вообще не развалилась.
И в unsloth это нормально не работает! В их кастомном "быстром" коде для Лоры это не учтено. Я попытался пофиксить это в исходниках, но grad_norm=inf. С lm_head, впрочем, проблем нет, и может быть этого будет достаточно. В итоге план такой:
- Переучить Сайгу с текущим 7к датасетом, но с lm_head и Лорой.
- Параллельно оценивается русская часть tagengo и капелька ещё 4 языков (чтобы научить модель переключать язык в зависимости от языка запроса).
- Переучить Сайгу на 7к + очищенном tagengo.
А если ничего не заработает, то 1) можно перейти на оригинальный шаблон 2) можно забить и пользоваться Suzume.
P.S. Есть ещё мини-прикол: в unsloth нормально не работает маска при батчинге в обучении, то ли из-за flash-attention, то ли из-за их оптимизаций.
Suzume огонь, 10/10 по первым примерами из тест-сета. Через час завершится оценка, вангую что-то типа 60-70% сырого винрейта по сравнению с gpt-3.5-turbo и точно лучше Сайги.
О, подъехала мультиязычная gpt-4 синтетика на запросах из lmsys-chat-1m: https://huggingface.co/datasets/lightblue/tagengo-gpt4/
Это мы щас вставим в сет...
Сайга-Гемма
Или переходим на обучение в axolotl.
Изначально идея этого эксперимента была в сравнении фреймворков для дообучения моделей, axolotl vs unsloth vs hf-trainer на новой базовой модели, Гемме.
Однако, unsloth до сих пор её не поддерживает, а hf-trainer на 24 Гб карточке вылетает по памяти, так что остался только axolotl.
Который всё равно работал только на A100 с 40 Гб.
Обучение было полностью в Колабе на A100: ссылка
Сама модель: ссылка
Училась только Лора, 6 часов.
Плюсы axolotl:
- Все параметры в одном конфиге.
- Очень удобный отладочный режим для просмотра финальной токенизации.
- Быстрая поддержка новых фичей и моделей.
Минусы axolotl:
- Довольно посредственные исходники с кучей багов.
- Как будто бы никакого выигрыша по времени и памяти по сравнению с самописным hf-trainer'ом.
- Нельзя легко сделать новый шаблон промпта (например с родным геммовским ), поэтому пришлось патчить токенизатор, чтобы переделать шаблон под ChatML.
Проблемы с Геммой:
- Странные OOM'ы на 24 Гб. Я пока не понимаю, как обучение Лоры с batch_size=1 может вылетать по памяти, когда с 13B моделями с теми же настройками всё было в порядке.
- repetition_penalty, отличный от 1.0, ломает модель и в HF, и в llama.cpp. Не я один это заметил, см. эту дискуссию.
- GGUF квантизация ниже 8 бит тоже ломает модель, она перестает вовремя генерировать EOS.
- Рандомные баги посреди генерации, отчасти возникающие из-за того, что нельзя поставить repetition_penalty.
Из-за всего этого SbS с Мистралем она заведомо проиграет. При этом в примерах, где багов нет, ответы вполне адекватные.
Модель пока не стоит использовать. Надеюсь через пару недель баги везде пофиксят, и станет лучше. Потенциал в ней точно есть.
Например, её можно дообучать на больших русских корпусах без изменения токенизатора.
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month, 2 weeks ago