Роздуми Спрощенця

Автор @yrashk


Простір для вивчення нової професії, зростання в кар’єрі або розвитку бізнесу👇🏻
Наша команда пише для вас найкращі та найцікавіші матеріали, які обов’язково допоможуть у вашому навчанні: https://genius.space/lab/
Last updated 1 month, 3 weeks ago

Тут ось яка ідея виникла: можливо іноді шукати програмістів з прямим релевантним досвідом у галузі це може бути свого роду ледарство. Це якось очевидно та й не оптимізує інші, непрямі навички, наприклад підходи до створення дуже швидкодійного софту, вирішення складних проблем, дотримання термінів, тощо
Як приклад: я от шукаю розробників із досвідом розробки розширень для постгресу, або навіть контрібуторів до постгресу. А може потрібно шукати хардкорних C++ гейм девелоперів які б зацікавились переходом на новий, відмінний стек та вдоволення потреб бізнес-клієнтів – та й перенесли б свої навички?
Знайомий запропонував інший приклад: шукати поміж Erlang розробників, бо вони всебічно розвинені та й ерланг системи завжди треба підтримувати і це тренує працювати з клієнтами ?
А ви як думаєте?
Тут ось яка ідея виникла: можливо іноді шукати програмістів з прямим релевантним досвідом у галузі це може бути свого роду …](/media/attachments/dec/decomplexifier/22.jpg)
Хвилинка самореклами. ?
Як ви можете пам’ятати, я Омнігресом займався з минулого року. Але в останні кілька місяців ми тут почали його трансформувати в реальний стартап щоб рухатись швидше і дати можливість тим хто з ним вирішує свої проблеми, мати реально якісний продукт.
Для тих хто не пам’ятає: Omnigres це такий uber-majestic monolith. Ми взяли постгрес і робимо з нього application runtime якій вміє ну майже все. І ваша бізнес логіка з нього не вилазить. Це робить розробку простішою, latency меншим, дає транзакціональність там де її ніколи не було, дає перспективи на дуже прості edge deployments, та ще багато чого.
Не всі з цим підходом згодні, але ми працюємо для тих кому це потрібно та чекаємо коли іншим набридне платити величезні гроші за мікросервіси які могли б бути SQL запитами ?
Чому я зараз вирішив прорекламуватись тут? Справа у тому що ми тепер починаємо будувати founding team інженерів. Це звичайно нелегка але цікава (для певної категорії людей) робота для тих хто готовий володіти проблемами та напрямками. Добра англійська абсолютно потрібна (інтернаціональна команда).
Початкова команда буде дуже невеличкою але рухатись будемо швидко.
Отже, приходьте до нашого гітхабу, та завітайте до діскорду де ми тусуємось. Ну або пишіть мені у телеграмі @yrashk
P.S. Вибачте за перерву у постах, останні місяці були ну дуже гарячі!
Хвилинка самореклами. ***?***](/media/attachments/dec/decomplexifier/21.jpg)
Коротка новина: нарешті зробив перший реліз досить нішевого інструмента, pg_yregress
Якщо ви знаєте що таке pg_regress але вам не дуже подобається з ним працювати, запрошую спробувати pg_yregress. Дозволяє структурувати тести краще, фокусуватись на предметі тестування, підтримує більш одного постгреса під тестом, тестування бінарних кодуваннь та т.і.
Максимально корисно для тестування розширеннь для Postgres, але цікаво подивитись і на інші юзкейзи.
Я тут написав статтю про архітектуру разом з автором SQLPage і вона зараз на front page Hacker News. Якщо знайдете, можете завітати до коментарів ?
Мене завжди дратував той факт, що для написання якоїсь бізнес-логіки на чомусь окрім SQL або PL/pgSQL, потрібно писати цей код всередині SQL файлу, наприклад:
`create function myfunction(myarg int) returns bool language python as $$
# а отут в нас Python
$$`
Бо з цього моменту нормально з редактором там вже не попрацюєш, а зовнішні інструменти взагалі не розуміють таку структуру.
Отже, сьогодні я написав фічу в Омнігресі, щоб можна було просто покласти цю функцію у .py-файл і воно його підхопить.
`# SQL[[create function times_ten(a integer) returns integer]]
return a * 10`
У подальшому можна поліпшити підтримку того ж Python та інших мов, зокрема, використовувати інформацію з анотацій та типів. Але наразі цей простий як пробка підхід працює будь-де (принаймні, я так думаю).
(Деталі: https://docs.omnigres.org/omni_schema/reference/#multi-language-functions)
А що ще вам заважає додавати логіку до бази даних?
Продовжуємо.
Перший день у Prolog був найважчим, адже кожні пʼять хвилин я намагався використовувати REPL (toplevel) щоб писати предикати прямо у запиті (без секції [user].). Втім, варто запам’ятати, що у цій штуці ми ставимо питання. А всі дефініції або у файлі, або
[user].
% тут щось описано
^D
Після усвідомлення цього, поїхало краще. Головна ідея, яка мені дуже подобається (принаймні, для певного класу проблем), це те, що правила описують “якщо X, то Y” і можна фокусуватись на результаті, а не на процесі його досягнення. Ми описуємо по суті відносини між речами. От простий приклад:
?\- length([1,2,3], L).
L = 3.
Тут, в принципі, все просто. Дали список, отримали довжину. Але все не так просто:
?\- length([1,2,3], 3).
true.
?\- length([1,2,3], 4).
false.
Тут ми бачимо, що насправді ми запитали, чи є довжина списку такою, як ми вказали (просто L у прикладі – це змінна без значення). Більше того, ми можемо давати складні умови з обмеженнями:
?\- use_module(library(clpfd)). % бібліотека для integer constraints
true.
?\- L \#< 4 \#\/ L \#>6 , length([1,2,3], L).
L = 3.
?\- L \#< 4 \#\/ L \#>6 , length([1,2,3,4,5,6], L).
false.
?\- L \#< 4 \#\/ L \#>6 , length([1,2,3,4,5,6,7], L).
L = 7.
Але навіть це ще не все, ми можемо згенерувати список заданої довжини:
?\- length(List, 5).
List = [_, , , , ].
?\- L \#< 4 \#\/ L \#>6 , length(List, L).
L = 0,
List = [] ;
L = 1,
List = [_] ;
L = 2,
List = [_, _] ;
L = 3,
List = [_, _, _] ;
L = 7,
List = [_, _, _, _, _, _, _] ;
...
Там ще дуже багато цікавого, але в мене тут простору не вистачить ?. Отже, це дуже цікавий інструмент для того щоб описувати складні системи. Мене дуже тішить, коли досить складні проблему описуються дуже лінійно завдяки тому що предикати можуть дати більш ніш одну відповідь (non-deterministic predicates).
Я вирішив поки що зупинитись на SWI Prolog, але є ще багато цікавих імплементацій, як відкритих, так і комерційних. SWI має багато фіч, та його досить легко додати до програм на C/Rust/т.і. програми (я навіть почав розробляти plprolog бо це буде дуже цікавий інструмент для експертних систем у постгресі). Після кількох тижнів з “чистим” прологом я перейшов на Logtalk для того щоб краще організувати мій код. Рекомендую: автор вже на протязі більш ніж 20 років працює над ним, і робить це дуже активно.
Чи варто спробувати Prolog? Так, абсолютно! Щонайменше, це дасть можливість подивитися на проблеми під іншим кутом. Власне, сама мова дуже мінімалістична і можна будувати прототипи та реальні системи досить швидко. Дуже рекомендую лекції Power of Prolog.
На скріншоті: поточна ітерація того, як виглядають описи пакетів.
Є питання? Пишіть!
**Продовжуємо.**](/media/attachments/dec/decomplexifier/17.jpg)
Кілька тижнів тому я вирішив опанувати нову (для мене) мову програмування — Prolog. Чому так сталося і чи було це варто робити?
Майже з самого початку розробки Omnigres мені хотілось зробити щось корисне для розповсюдження розширень (extensions) для Postgres. Чому? Система управління розширеннями в постгресі досить обмежена: вона дає можливість знайти SQL файли для інсталяції або апгрейду/даунгрейду і робить заміну певних строк у цих файлах (типу власника, схеми чи шляху до .so-файлу). Але все, що стосується зборки та розповсюдження, – біда. Розбирайтесь самі. Найвідоміша система pgxn по суті є каталогом і мйже всі моменти стосовно залежностей майже повністю залишаються проблемою користувача. Нещодавно анонсованийdatabase.dev займається тільки TLE (trusted language extensions). Також нещодавно анонсований Trunk є трохи кращим, але досить обмеженим: runtime залежності не вирішені, і все досить сильно повʼязане наразі з докером.
Все це мене не досить влаштовувало. Я хочу фантастичного D3X (Development, Debugging and Deployment Experience): щоб все працювало на компʼютерах розробників (так, навіть на macOS і без постгресу у докері), щоб можна було інсталювати розширення із залежностями з рідних пакетів тієї дістрібуції лінукса що у вас на сервері, щоб можна було вказати залежності між розширеннями, пакетами, постгресом та ін.
Отже, я придбав цікавий домен (ще не анонсовано, але це postgres.pm) і вирішив зайнятись проблемою.
Було багато ідей як це зробити. Але всі вони були навколо того факту що якщо ми хочемо будувати розширення у невідомих обставинах, нам потрібно щось типу експертної системи. А також того, що потрібна якась проста нотація для опису пакетів. Спочатку я намагався зробити це на CLIPS, але воно працює найкраще коли всі факти відомі і треба з ними щось зробити. У нашому випадку, це не дуже практично бо для багато чого треба опитувати систему напряму. І опитати про все-все-все нереально. Отжеж, я дійшов до потреби у backward chaining, спробував його реалізувати у вигляді патча до CLIPS, але засів там надовго бо це було не дуже просто.
Тут я вирішив себе перебороти, і спробувати щось типу Prolog’у. Бо я був в курсі, але ніколи не використовував. Тим паче що там є реалізації constraints що дуже корисно для штук типу пошуку сумісних версій. Та й синтаксис мене не дуже лякав, бо я багато років на Erlang писав.
Продовження у наступному пості.
P.S. Хто вгадає мій промпт для картинки?
Кілька тижнів тому я вирішив опанувати нову (для мене) мову програмування — Prolog. Чому так сталося і чи було це …](/media/attachments/dec/decomplexifier/16.jpg)
Короткий допис/опитування.
У поточному проекті (Омнігрес) моя головна мета — покращення робочого досвіду (development experience, DX) роботи з базою даних. Бо будемо чесні, він трішки засів у минулому, де були великі сервери і всі зміни проводились через DBA.
Нещодавно я працював над концепцією віртуальних файлових систем для постгресу (VFS) та її використанні для розгортання DDL та функцій як локально так і на продакшн (наприклад з Git VFS).
Але сьогодні мені хотілося би порушити трохи інший аспект: інтерактивні клієнти БД. Ми маємо REPL-подібні клієнти типу psql, є багато графічних та веб клієнтів. Проте, мені здається що концептуально багато з них відображають практики та підходи минулих часів. Можливо, пора критично переглянути робочий досвід у цьому напрямку.
Отже я хотів би запитати вас:
Якими клієнтами БД ви користуєтесь, чому, і що в них дратує чи навпаки? Як ви їх використовуєте в процесі розробки?
Короткий допис/опитування.](/media/attachments/dec/decomplexifier/15.jpg)
Не писав деякий час, вибачте (багато чого відбувається!). Дуже короткий допис сьогодні, але по суті.
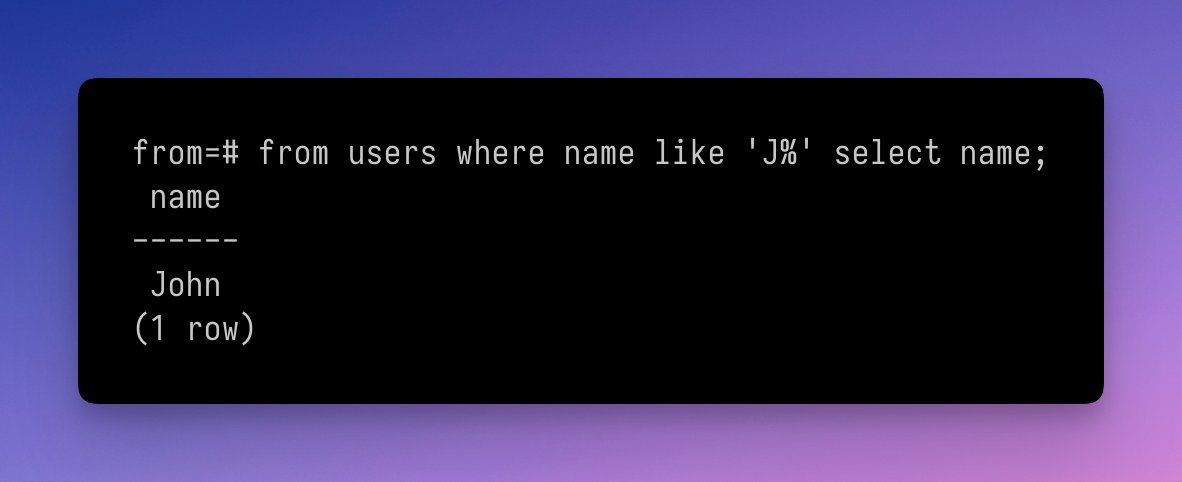
Коли SQL формувався, так сталось що порядок у select-а, умовно кажучи, такий: “вибери ЦЕ, ЗВІДСИ[, якщо підпадає під УМОВИ]”
Але ж це реально незручно у практиці у сьогоднішніх умовах. Якщо починаєш писати select nam, то твій редактор не має можливості зробити автокомпліт. Бо ще ж не додано інформації про це. І от виходить що пишеш select from users, потім повертаєшся до селекту і починаєш додавати поля.
А ще отака біда: складні запити багаторядкові, і коли працюєш з такими, виходить що доводиться “стрибати” між початком запиту і кодом який власне опрацьовує результати, щоб перевірити що ми там, власне, понавибирали.
Я не перший з цього приводу переймався, і не я останній. Але стало у якійсь момент цікаво: а власне наскільки складно було б додати такий варіант select, який б вирішував ці проблеми? Звісно, з технічної сторони – я не маю й гадки стосовно того наскільки складно щось додати до стандарту. Отже, технічно, та й до Постгресу, звісно, бо я дуже активно з ним працюю.
Виявляється, не дуже. Власне, поки що обійшлося невеличкими змінами до граматики. На додаток до класичного select ... from ..., написав правила для from ... select .... Запрацювало! (дивись картинку)
Якщо комусь цікаві деталі, мій нашвидкоруч зроблений патч.
P.S. Я спробую знайти час розібратись як додати такий синтаксис до Омнігресу без того щоб використовувати пропатчений Постгрес. Є ідеї!
Не писав деякий час, вибачте (багато чого відбувається!). Дуже короткий допис сьогодні, але по суті.](/media/attachments/dec/decomplexifier/14.jpg)
Простір для вивчення нової професії, зростання в кар’єрі або розвитку бізнесу👇🏻
Наша команда пише для вас найкращі та найцікавіші матеріали, які обов’язково допоможуть у вашому навчанні: https://genius.space/lab/
Last updated 1 month, 3 weeks ago