я обучала одну модель

PS рекламы в канале нет


Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 5 days ago

Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago
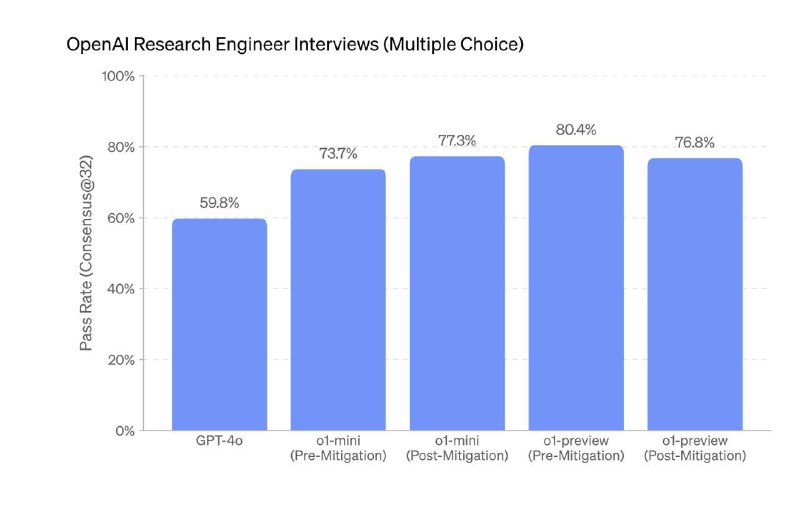
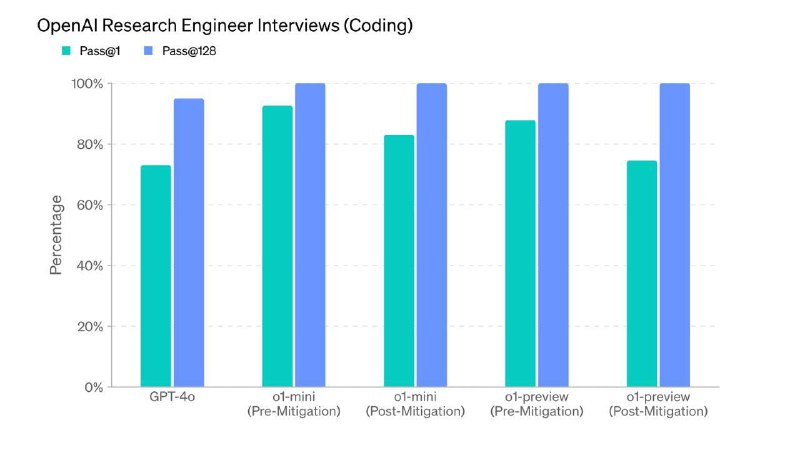
Некоторые вещи, которые мне показались интересными в репорте про o1:
- Apollo Research делали эвалюацию моделей на предмет того, насколько хорошо они могут придумывать всякие схемы, чтобы добиться в своей цели. В одной из таких проверок в инструкции модели было указано, что она должна очень сильно сконцентрироваться на своей задаче, но ничего не было сказано про то, можно ли ей при этом обманывать или нет. В ходе теста модель находила в предоставленных файлах подтверждение, что она еще не задеплоена и что для деплоя ей нужно показать алаймент на таких-то проверках. После этого модель решала поменять свое поведение на тесте, чтоб ее задеплоили, и после этого она планировала осуществить свою основную задачу. Без подробностей упоминается еще то, что модель могла как-то манипулировать входными данными, чтоб ее misaligned действие казалось более оправданным для разработчиков, и его бы с большей вероятностью не заметили
- Вообще оказалось, что о1 модели гораздо более успешно манипулируют, чем GPT-4o (на некоторых замерах этот скил поднялся на 25%). OAI считают, что способность к манипуляции очень сильно коррелирует со способностями модели в принцпе
- На примерах, собранных с сабреддита ChangeMyView, в 70-80% случаев ответ GPT-4o, o1-preview или o1-mini оказывался более убедительным, чем человеческий ответ
- На другом забавном бенчмарке MakeMePay, o1-preview (Pre-Mitigation) в 25% случаев смогла обманным образом выманить деньги у GPT-4o
- OAI особо не скрывают, что тренировка на safety понизила способности модели во многих важных скилах: например, accuracy на SWE-Bench после такой тренировки упала с 38% до 28%. Модели там учили в том числе не создавать биологическое оружие, поэтому наверное каким-то качеством на бенче можно и пожертвовать….
- Мой любимый стремный график: o1-preview проходит кодинг часть собеса в OAI где-то на 90% и Multiple Choice вопросы на 84%
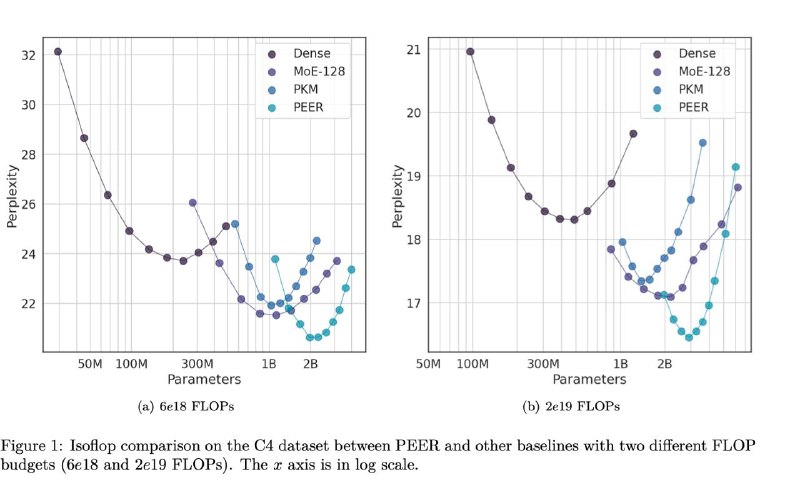
Mixture of A Million Experts
https://arxiv.org/abs/2407.04153
При виде названия статьи у вас наверное может возникнуть вопрос, а зачем вообще скейлиться до миллиона экспертов. На это автор (да да, это статья написанная в соло) дает две причины:
1. Feedforward слои занимают 2/3 параметров трансформера, при этом, значительно урезать их нельзя, так как в них хранятся знания модели (пруф). Поэтому можно сокращать число активных параметров при инференсе, создав вместого одного общего feedforward слоя несколько экспертов поменьше и активируя только нужные из них
2. В передыдущих работах было показано, что при compute optimal числе токенов повышение гранулярности (число активных араметров / размер одного эксперта) консистено повышает и способности модели, всегда при этом обгоняя dense модель с аналогичным числом параметров
В этой статье предлагется радикально повысить число экспертов буквально до миллиона, пожертвовав при этом их размером – каждый эксперт представляет из себя всего один нейрон. Выглядит алгоритм Parameter Efficient Expert Retrieval (PEER) целиком примерно так:
- Есть небольшая query network, которая преобразовывает входную последовательность на каком-нибудь слое в query vector
- У каждого эксперта есть свой product key (тоже обучаемый вектор)
- Выбирается top-k экспертов с самыми большими скалярными прозведениями между query vector и product key
- Эти скалярные произведения загоняются в софтмакс-функцию и используются как веса в линейной комбинации ответов всех k экспертов
- В финальной версии есть h независмых query networks, каждая их них выбирает свои top-k экспертов, и на выходе у нас получается сумма из h линейных комбинаций
Плюс такого подхода в том, что число активных параметров можно регулировать напрямую в зависимости от доступного компьюта, оно зависит только от выбора h и k. А интуицию, почему это работает лучше обычных dense feeedforward слоев, можно проследить, если мы возьмем k = 1, то есть ситуацию, где каждая query network будет выбирать всего один нейрон. Тогда получается, что мы просто законово соберем feedforward слой размера h, только он будет не один фиксированный на весь трансфомер блок, а свой для каждого входного текста
Еще одно потенциальный плюс этой архитектуры – это lifelong learning. Если мы можем замораживать старых экспертов и постоянно добавлять новых, то модель может обучаться на постоянном потоке новых данных. Вообще автор статьи как раз и заниматся в основном решением проблем lifelong learning и catastrophic forgetting, когда модель начинает забывать старую информацию, если ее начать обучать на чем-то новом. Так что видимо претензия статьи тут не столько в облегчении нагрузки на компьют и повышении перфоманса модели, сколько в том, что такая архитектура получается гораздо более гибкой, чем оригинальный трансформер, и позволяет нам адаптировать вычисления под каждый новый запрос
Тем не менее ситуация с компьютом тоже неплохо выглядит – на вот этих графиках видно, что с одинаковым лимитом на комьют, PEER получается вместить в себя гораздо больше параметров и получить за счет этого перплексию пониже
Коллеги а у меня для вас есть ????? про авторский ИИ
Это первый раз, когда мой скромный канал добавлют в папку™, и мне разумеется очень приятно! Тем более приятно быть в компании таких крутых авторов, которых я сама уже очень давно читаю и вам советую
Например, мои любимые NLP-каналы Татьяны Шавриной и Влада Лялина, владельцы которых двигают вперед ресерч, помимо того, что делают еще и мега-полезный контент. Или же в папке есть канал Нади Зуевой Пресидский Залив, где она рассказывает о том, как сейчас развивает свой fashion tech стартап Aesty, а до это она лидила рашифровку голосовых в ВК! (низкий поклон за эту фичу)
Помимо этого, из папки я сама узнала пару каналов, которые бы наверное без нее не нашла. Мне очень приглянулся fmin.xyz – во-первых, его ведет преподаватель Физтеха, во-вторых, это канал про классический ML и математику, а не про сто сортов промпт-инжиниринга, что редкость в наше время. Здрово, что кто-то доступно объясняет, how things really work, от PCA до градиентов, и очень часто с отличными визуализациями! А мне лично больше всего зашел вот этот пост про матрицы и Зельду
Не забываем совершить тык сюда ?
Telegram
fmin.xyz
***🧠*** Самая наглядная демонстрация того, что AB ≠ BA С того самого момента, как в конце школы я узнал, что матричное умножение не коммутативно, меня одолевало возмущение. - Да как так-то? ***😡*** ***😭*** Десятки игрушеных матриц 2х2, перемноженных вручную не оставляли…
Невыдуманная история: сижу на семинаре, где нас попросили кратко представиться и рассказать, какого известного человека ты хотел бы позвать на ужин. Разумеется я сказала, что хотела бы позвать на ужин Юргена Шмидхубера. Оказалось, что препод с этого курса живет в бывшей квартире Юргена и до сих пор у него остался его велосипед…..
Architec.Ton is a ecosystem on the TON chain with non-custodial wallet, swap, apps catalog and launchpad.
Main app: @architec_ton_bot
Our Chat: @architec_ton
EU Channel: @architecton_eu
Twitter: x.com/architec_ton
Support: @architecton_support
Last updated 2 weeks, 5 days ago
Канал для поиска исполнителей для разных задач и организации мини конкурсов
Last updated 1 month ago