Concise Research


Telegram stands for freedom and privacy and has many easy to use features.
Last updated 1 year ago

Sharing my thoughts, discussing my projects, and traveling the world.
Contact: @borz
Last updated 1 year ago

Official Graph Messenger (Telegraph) Channel
Download from Google Play Store:
https://play.google.com/store/apps/details?id=ir.ilmili.telegraph
Donation:
https://graphmessenger.com/donate
Last updated 1 year, 7 months ago
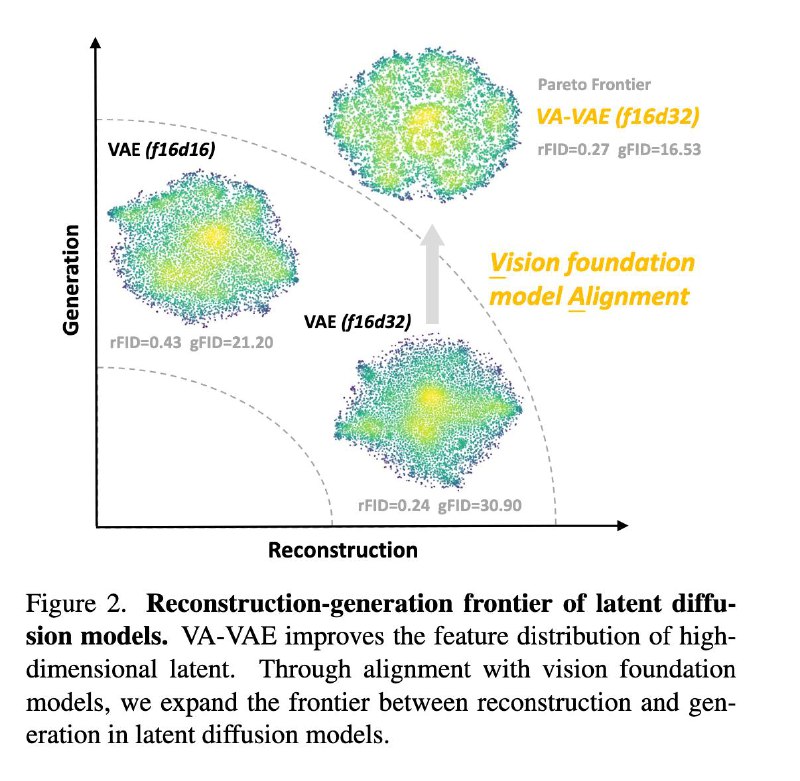
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
[код и веса]
Выбор представления для обучения латентной диффузии - важнейший фактор качества и скорости обучения модели.
Более высокая размерность
латентного пространства улучшает качество реконструкции. Обычно она достигается путём увеличения числа каналов. VAE первых моделей семейства SD имели 4 канала, у FLUX и SD3 уже 16, а SANA - 32.
Более низкая размерность
латентного пространства упрощает задачу обучения генеративной модели. Если размерность все-таки хочется держать высокой, то можно компенсировать сложность увеличением модели и компьюта, но это дорого.
Интересно, что проблемы связанные с большой размерностью ранее обсуждали в основном для дискретных токенизаторов. Для них известно, что большие кодбуки плохо утилизируются. Авторы этой работы анализируют распределение латентов непрерывных VAE и приходят к такому же выводу. Идея работы в том чтобы заалайнить латенты с фичами visual foundation model, тем самым улучшив их качество с точки зрения обучения на них генеративных моделей.
Метод
Основной вклад работы - двухкомпонентный лосс, который алайнит VAE латенты Z с фичами DINOv2 F. Для этого Z линейно отображают в размерность F получая Z’, после чего:
1️⃣ Поэлементно минимизируют косинусное расстояние между Z’ и F
2️⃣ Минимизируют разницу косинусных расстояний между элементами Z’ и F
Оба компонента считают с отступом так, чтобы только большие отклонения вносили вклад в лосс, а между собой компоненты взвешивают пропорционально их вкладу.
Эксперименты
За основу берут ванильный LDM сетап с VQ-GAN токенизатором (f16d32, f16d16), но без квантизации. На его латентах учат DiTы от 0.1B до 1.6В c полным фаршем из RF, подбора adam.beta2, bfloat16 и RMSNorm для стабилизации, SwiGLU и RoPE. Полученная серия моделей LightningDiT сходится к FID 1.35 на ImageNet 256, причем значение 2.11 получается всего за 64 эпохи.
Выводы
В статье настораживает почти полное отсутствие примеров реконструкций предложенных VAE и аблейшенов влияния примочек для DiT на рост качества относительно бейзлайнов. Нравится движение в сторону недоизученной темы оптимальных пространств для обучения генеративок

Давайте поговорим про GAN.
В последнее время принято друг за другом повторять: GAN — парадигма прошлого, диффузия и авторегрессия рулят. Тем не менее, даже сейчас, не смотря на доминирование диффузии в text-to-image, GAN находят применение в Super Resolution и обучениях VAE, а также используются в методах дистилляции (ADD) и альтернативных архитектурах диффузии (PaGoDa). При этом, GAN имеют очевидные проблемы. Работы ниже конректизируют проблемы и предлагают способы их решения.
Towards a Better Global Loss Landscape of GANs
[NeurIPS 2020, код/веса]
Авторы выделяют две основные проблемы при обучении GAN:
1. Mode collapse —падение разнообразия генераций)
2. Divergence — расхождение процесса обучения
Для этого проводят анализ поверхности лоссов наиболее популярных вариантов GAN.
Предлагается поделить все GAN на два семейства по типу используемых лосс функций:
1. Separable-GAN — почти все популярные GAN, где D независимо оценивает правильность real/fake примеров. Сюда относят классические JS-GAN, W-GAN
2. Relativistic-GAN — модели, в которых D оценивает реальность fake примера относительно соответствующего ему real примера. Основной пример - RpGAN.
Авторы показывают, что эта разница принципиальна. Separable-GAN работает в предположении, что все real и fake данные можно разделить одной границей. Тогда задачей G становится минимальный перенос fake примеров за эту границу. Таких решений экспоненциально много, многие из них вырождены, что и приводит к проблемам. В то же время, авторы показывают, что обучение Relativistic-GAN такой проблемой не обладает, а каждый минимум является глобальным.
The GAN is dead; long live the GAN!
A Modern Baseline GAN
[NeurIPS 2024, код]
Всё сказанное выше правда, все минимумы - глобальные, вот только никто не сказал, что градиентный спуск может легко найти их. На практике, RpGAN без доп регуляризаций не всегда сходится.
Вклад этой работы в том что авторы:
1️⃣ Анализируют то какие именно регуляризации полезны для RpGAN, получается, что это комбинация R1 + R2 (gradient penalty для D и G), называют модель R3GAN
2️⃣ Обнуляют все трюки из StyleGAN2, после чего заново подбирают и аблейтят архитектуру
На выходе получают модель с ResNeXt-ify архитектурой для G и D и отстутствием каких-либо трюков кроме RpGAN + R1 + R2 лосса. Финальная версия улучшает FID на FFHQ 256 c 7.52 до 7.05 при сохранении размеров G и D.
Итог
Очень нравятся работы про раздебаг и упрощение систем, когда вместо yet another заплатки находят и устраняют проблему. Переносимость результатов на смежные задачи и бОльшие масштабы требует доп. проверки.
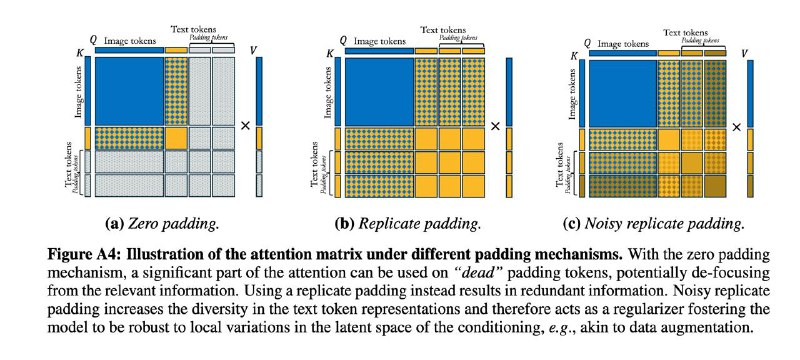
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
[NeurIPS’24, кода/весов нет]
Одна из основных проблем в исследовании диффузионок - отсутствие полноценных сравнений между компонентами разных подходов. Большинство крупных релизов (SD разных версий, EMU, Imagen etc.) сопровождается тех. репортом, в котором поменяно всё сразу. В DL мы занимаемся построением моделей по данным и понятно, что они оказывают ключевое влияние. Но как быть с остальными компонентами системы: архитектурой, постановкой диффузии, кондишенингом?
Авторы воспроизводят кучу моделей для “наведения порядка” хотя бы на публичных датасетах, фиксируя компьют, постановку диффузии и гиперпараметры для честного сравнения. Далее основные выводы.
Архитектура
Сравнивали, выровняв по параметрам:
— U-Net из SDXL
— Ванильный DiT
— Masked DiT (mDiT-v2)
— PixArt DiT
— mmDiT из SD3
Все модели текст-кондишенили на CLIP ViT-L/14, обучение DiT’ов стабилизировали используя RMSNorm.
По FID почти всюду победила архитектура mmDiT. Интересно, что ранее в работе по Scaling Laws уже отмечали эффективность SDXL U-Net’a. Видимо, в Stability годные спецы по архитектурам.
Кондишенинг
Тут авторы наворотили знатно, адресуя сразу несколько вопросов:
1️⃣ Использование control conditions (это когда в модель подаётся доп инфа про размер картинки/кропа и тд).
— Лучше подавать не бинарно (обычно вес выставляют в 0 или 1), а по косинусному расписаню, где ближе к шуму вес максимальный
— Лучше не использовать сомнительные аугментации вроде флипов даже если вы явно даёте это знание модели потому что может ломаться сответствие картинки с текстом
— Аугментации кроппингом могут быть полезны если размер явно подать согласно расписанию
2️⃣ Текстовый conditioning.
— Стандартно CLIP кодирует в 77 токенов, некоторые тексты могут быть короче. Обычно, в таких случаях последовательность падят нулями. Предлагается noisy replicate padding - копируем (часть) токенов, чуть зашумляем, stonks 📈
Обучение
— Файнтюниться под целевое распределение полезно даже если у вас самый широкий и разнообразный претрен (ImageNet22k)
— Полезно разбивать претрен на стадии по разрешению: сначала учимся на лоу резах, потом на хай резах 🎵
— Кропать лоу резах и хай резах нужно по-разному из-за разного среднего размера объектов на картинке
— Для высоких разрешений полезно пошатать расписание шума (вспомнилась Simple Diffusion)
— Подбор позиционных эмбедингов улучшает динамику обучения
Итого
Аккуратное, в меру интересное сравнение разных компонентов диффузионного пайплайна. Как всегда не понятно насколько это переносимо на обучения с датасетами из О(1В) семплов и замерами на human eval вместо FID.

До начала октября 2024, генерация картинок и видео существовали как области, которые не объединяло ничего кроме вялого перетекания идей. Одновременное появление сразу трёх работ на стыке модальностей намекает на актуальность. Подходы разные, давайте разбираться.
Movie Gen: A Cast of Media Foundation Models
Топовый тех. репорт от экстремистов с кучей технических подробностей. Детали разобраны тут и в подробном повторении не нуждаются. Сейчас нам интересно, что этот подход наиболее простой и естественный: чуть адаптируем LLAMA трансформер, обучаем Video-VAE, а дальше учим end-to-end диффузию сначала на картинках (воспринимая их как видео из одного кадра), потом на видео с постепенным увеличением разрешения. Минус в том что подход для богатых: предлагается учить 30В модельки на 6500 H100.
JVID: Joint Video-Image Diffusion for Visual-Quality and Temporal-Consistency in Video GenerationАкадемические исследователи предлагают разменять баснословный компьют на усложнение семплирования. Вместо обучения единой модели предлагается отдельно учить картиночную и видео модели и комбинировать за счет предложенного механизма попеременного семплирования. Работает это в случае если для обеих моделей прямой процесс задан одинаково. Для обучения используют всего 64 A100, но и качество/разрешение тут более скромные. Насколько хорошо подход обобщается на масштабы SOTA моделей не ясно.
Pyramidal Flow Matching for Efficient Video Generative Modeling
[код, веса]~~Вижу флоу матчинг - ставлю лайк~~. Хайпанувшая работа где китайский студент за ~~плошка риса~~ 20к ГПУ часов собирает космолёт, порождающий весьма консистентные видосики. В методе есть всё:
- Модная диффузия позволяет интерполировать между разрешениями. Это позволяет экономить на расшумлении близких к полному шуму латентов низком разрешении и только финальных шагах в высоком
- Авторегрессионная компонента позволяет лучше сохранять консистентность кадров. Для этого прошлые кадры в низком разрешении используются в качестве условия для генерации текущего кадра.
Благодаря такой архитектуре можно воспринимать отдельные кадры как картинки или подавать в модель в качестве первого кадра произвольное изображение и делать image-to-video.
- Трансформеры, эффективность, код, аблейшены.
Опыт говорит, что простота метода побеждает оптимизацию вычислительной сложности, но время покажет.
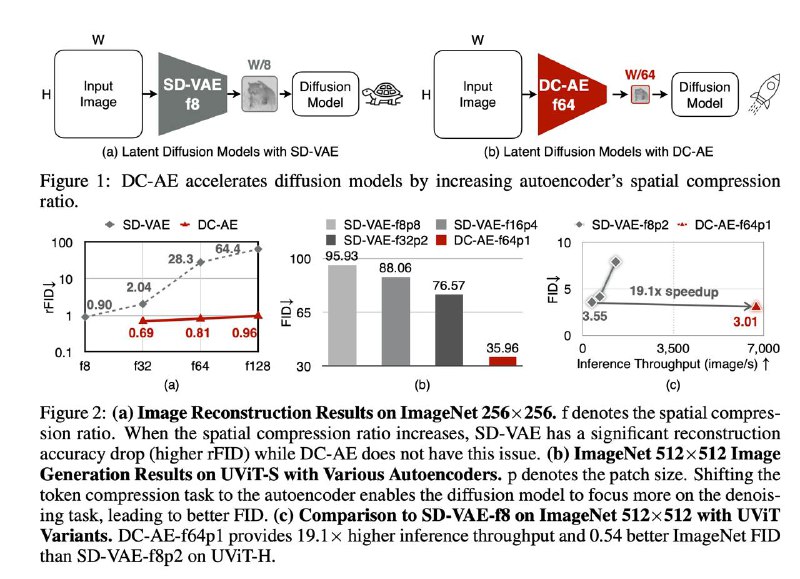
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
[код обучения и инференса, веса]
Вслед за КПД, уже разобравшим эту работу с акцентом на мотивацию и эксперименты, предлагаю свой взгляд.
Прежде, основной фокус диффузионных команд был направлен на улучшение генеративной модели, а латентное пространство всегда формировали с помощью x8 SD-like автоэнкодера (АЕ). Вообще, х8 - это уже довольно много, но все же 4к генерации не сделаешь из-за того что латентной диффузии прийдется работать в разрешении 512, что долго/дорого.
Работа хороша тем что предлагаются фиксы конкретных проблем, а не просто yet another модель, которая почему-то магически работает.
Хотелки, проблемы и решения
1️⃣ Хотим х32, х64, х128 АЕ
Проблема: если наивно настакать слоёв, возникают проблемы с оптимизацией: добавление каждого следующего блока ухудшает качество реконструкции по rFID
Решение: добавим space-to-channel операцию и residual connection.
Суть в том что обычный residual connection - это сложение или конкатенация с активацией с тем же пространственным разрешением. Но в AE разрешение изменяется х2 после каждого upsample/downsample блока. Поэтому предлагается делать reshape + поканальное усреднение чтобы получить отображение: [H, W, C] \-> [H/2, W/2, 2C]. Сами по себе residuals добавлять нужно, но открытым остаётся вопрос насколько важно использовать именно такую реализацию (ablations нету)
2️⃣ Хотим хорошую обобщаемость между разрешениями. То есть наш АЕ должен одинаково хорошо реконструировать и 512 и 4к картинки
Проблема: дорого (или даже невозможно) адаптировать через обучение на 4к картинках, а по-другому не обобщается (низкое качество реконструкции)
Решение: разобьем обучение на три стадии:
- Учим всю сеть С L1 + perceptual лоссами на low rez картинках
- Учим всю нижние блоки АЕ с L1 + perceptual лоссами на high rez картинках
- Учим последнюю свертку декодера с GAN лоссом
У каждой стадии своя цель, но сводится всё к тому чтобы избежать обучения всей модели с GAN лоссом потому что, по утверждениям авторов, это плохо влияет на латентное пространство.
В экспериментах, авторы учат class-cond и text-cond генерацию на разрешениях 512 и 1024, получают не идеальные, но достойные картинки при ускорении up to x19 за счет снижения размерности лантентов. Особенно сильно это бустит трансформерные архитектуры денойзеров, ведь теперь не нужно выбрать большой patch size для того чтобы удешевить attention.
Очень любопытно сменит ли эта модель тренд на то за счет чего достигается ускорение в диффузионках.
](/media/attachments/c_r/c_research/185.jpg)
Sample what you can’t compress
[Google и xAI код не выкладывают]
Картиночные автоэнкодеры (АЕ) используются для обучения диффузионных и авторегрессионных моделей на их скрытых представлениях. При этом, для обучения самих АЕ, обычно используют комбинацию реконструкционных лоссов (L1, L2, LPIPS, DreamSIM, DISTS etc.) и GAN лосса. Добавление GAN лосса делают для увеличения четкости и реалистичности, без него реконструкции получаются размытыми.
Авторы задаются вопросом: если диффузия сейчас основная генеративная парадигма, почему мы все еще учим АЕ с GAN лоссом?
Может показаться, что статья просто про замену GAN на диффузию -> stonks ? (зумеры переизобрели писксельную диффузию в пространстве высокой размерности).
На самом деле это не совсем так. Обратим внимание на основную схему: на ней есть два декодера и оба важны для качества и сходимости. D_refine - это U-Net, действительно представляющий собой пиксельную диффузию. Но важно, что он также обуславливается на выход D_refine, то есть на результат кодирования-декодирования AE. Мне это напоминает то как работают диффузионные SR модели (SR3), в которых к основному входу x_t приконкачивают бикубик апскейл LR картинки y.
Использование условия на выход D_init имеет и другой плюс - можно использовать CFG. Для этого в ходе обучения условие дропают в 10% случаев, а на инференсе экспериментально подбирают оптимальный CFG scale, что в итоге улучшает качество.
В экспериментах авторы проверяют, что их AE приводит:
- К более хорошим реконструкциям, особенно на высоких степенях компрессии (когда мало каналов в латентах);
- К более качественным (по FID) class-cond диффузионкам, обученным на этих латентах.
У подхода есть очевидный минус связанный с применением диффузии - увеличение стоимости обучения и инференса. А еще совершенно не ясно почему такое обучение даёт более хорошие латенты.

Telegram stands for freedom and privacy and has many easy to use features.
Last updated 1 year ago
Sharing my thoughts, discussing my projects, and traveling the world.
Contact: @borz
Last updated 1 year ago
Official Graph Messenger (Telegraph) Channel
Download from Google Play Store:
https://play.google.com/store/apps/details?id=ir.ilmili.telegraph
Donation:
https://graphmessenger.com/donate
Last updated 1 year, 7 months ago