Deep Learning, Computer Vision and NLP

Computer Vision ?️ &
#Ai ?
Get #free_books,
#Online_courses,
#Research_papers,
#Codes, and #Projects,
Tricks and Hacks, coding, training Stuff
Suggestion @AIindian

Community chat: https://t.me/hamster_kombat_chat_2
Website: https://hamster.network
Twitter: x.com/hamster_kombat
YouTube: https://www.youtube.com/@HamsterKombat_Official
Bot: https://t.me/hamster_kombat_bot
Last updated 10 months, 4 weeks ago

Your easy, fun crypto trading app for buying and trading any crypto on the market.
📱 App: @Blum
🤖 Trading Bot: @BlumCryptoTradingBot
🆘 Help: @BlumSupport
💬 Chat: @BlumCrypto_Chat
Last updated 1 year, 4 months ago

Turn your endless taps into a financial tool.
Join @tapswap_bot
Collaboration - @taping_Guru
Last updated 11 months, 1 week ago
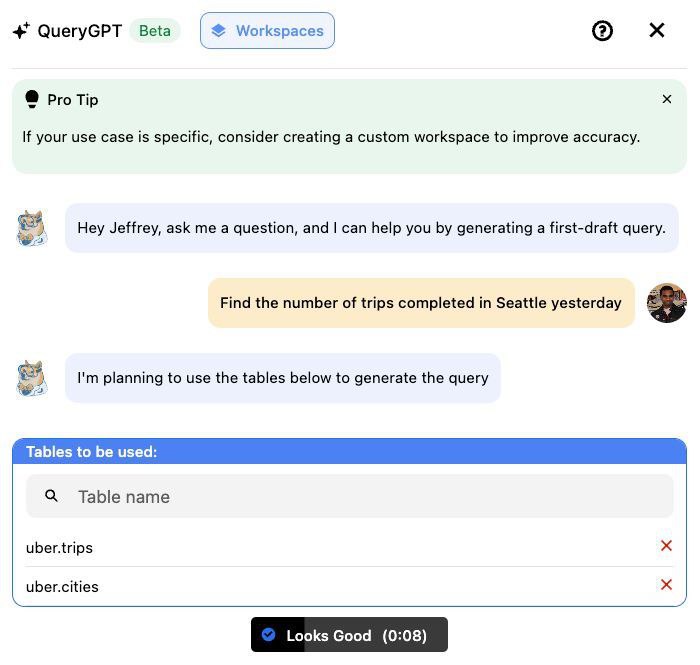
Uber used RAG and AI agents to build its in-house Text-to-SQL, saving 140,000 hours annually in query writing time. ?
Here’s how they built the system end-to-end:
The system is called QueryGPT and is built on top of multiple agents each handling a part of the pipeline.
-
First, the Intent Agent interprets user intent and figures out the domain workspace which is relevant to answer the question (e.g., Mobility, Billing, etc).
-
The Table Agent then selects suitable tables using an LLM, which users can also review and adjust.
-
Next, the Column Prune Agent filters out any unnecessary columns from large tables using RAG. This helps the schema fit within token limits.
-
Finally, QueryGPT uses Few-Shot Prompting with selected SQL samples and schemas to generate the query.
QueryGPT reduced query authoring time from 10 minutes to 3, saving over 140,000 hours annually!
Link to the full article: https://www.uber.com/en-IN/blog/query-gpt/?uclick_id=6cfc9a34-aa3e-4140-9e8e-34e867b80b2b
How Much GPU Memory Needed To Server A LLM ?
This is a common question that consistnetly comes up in interview or during the disscusiion with your business stakeholders.
And it’s not just a random question — it’s a key indicator of how well you understand the deployment and scalability of these powerful models in production.
As a data scientist understanding and estimating the require GPU memory is essential.
LLM's (Large Language Models) size vary from 7 billion parameters to trillions of parameters. One size certainly doesn’t fit all.
Let’s dive into the math that will help you estimate the GPU memory needed for deploying these models effectively.
??? ??????? ?? ???????? ??? ?????? ??
General formula, ? = ((? * ???? ??? ?????????)/?????? ???????) * ???????? ??????
Where:
- ? is the GPU memory in Gigabytes.
- ? is the number of parameters in the model.
- ???? ??? ????????? typically refers to the bytes needed for each model parameter, which is typically 4 bytes for float32 precision.
- ?????? ??????? (q) refer to the number of bits typically processed in parallel, such as 32 bits for a typical GPU memory channel.
- ???????? ?????? is often applied (e.g., 1.2) to account for additional memory needed beyond just storing parameters, such as activations, temporary tensors, and any memory fragmentation or padding.
?????????? ???????:
M = ((P * 4B)/(32/Q)) * 1.2
With this formula in hand, I hope you'll feel more confident when discussing GPU memory requirements with your business stakeholders.
Best article on GenAI getting started
https://blog.bytebytego.com/p/where-to-get-started-with-genai
The matrix calculus for Deep Learning. Very well written. https://explained.ai/matrix-calculus/
Community chat: https://t.me/hamster_kombat_chat_2
Website: https://hamster.network
Twitter: x.com/hamster_kombat
YouTube: https://www.youtube.com/@HamsterKombat_Official
Bot: https://t.me/hamster_kombat_bot
Last updated 10 months, 4 weeks ago
Your easy, fun crypto trading app for buying and trading any crypto on the market.
📱 App: @Blum
🤖 Trading Bot: @BlumCryptoTradingBot
🆘 Help: @BlumSupport
💬 Chat: @BlumCrypto_Chat
Last updated 1 year, 4 months ago
Turn your endless taps into a financial tool.
Join @tapswap_bot
Collaboration - @taping_Guru
Last updated 11 months, 1 week ago