Data Science by ODS.ai ?


Community chat: https://t.me/hamster_kombat_chat_2
Website: https://hamster.network
Twitter: x.com/hamster_kombat
YouTube: https://www.youtube.com/@HamsterKombat_Official
Bot: https://t.me/hamster_kombat_bot
Last updated 12 months ago

Your easy, fun crypto trading app for buying and trading any crypto on the market.
📱 App: @Blum
🤖 Trading Bot: @BlumCryptoTradingBot
🆘 Help: @BlumSupport
💬 Chat: @BlumCrypto_Chat
Last updated 1 year, 5 months ago

Turn your endless taps into a financial tool.
Join @tapswap_bot
Collaboration - @taping_Guru
Last updated 1 year ago
 — это коллекция лучших …](/media/attachments/ope/opendatascience/2177.jpg)
? awesome-claude-prompts — это коллекция лучших промптов для использования с языковой моделью Claude!
? В репозитории собраны примеры для самых разных задач, от анализа текста до написания кода, что делает его полезным для разработчиков, маркетологов, студентов и многих других пользователей.
? Github
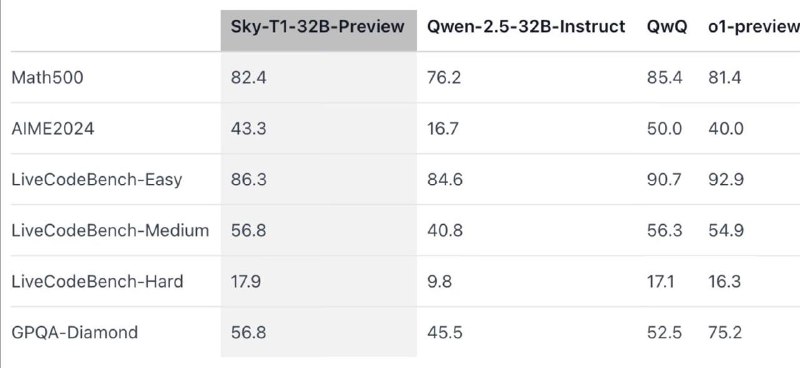
*? Sky-T1-32B-Preview 32B - 450$ - это все, что вам нужно, чтобы обучить свою собственную O1 ?***
Модель достигает конкурентоспособных результатов в рассуждениях и кодинге, 82.4 в Math500, 86.3 в LiveCode-East по сравнению с QwQ (85.4, 90.7) и o1-preview (81.4, 92.9) ?
Это новая O1 - подобная модель с открытым исходным кодом, обученная за < 450$, полностью открытый исходный код, 17K обучающих данных, , модель превосходит Qwen-2.5-32B-Instruct по всем бенчмаркам ?
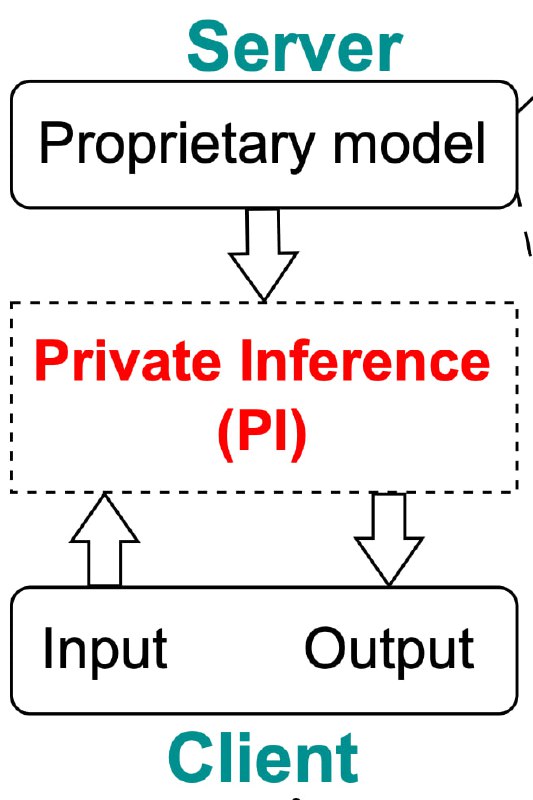
Как выкинуть из трансформера все нелинейности и причём тут приватность?
Вы задумывались, насколько безопасно задавать «приватные» вопросы в чатГПТ? Где продать чужую почку и т.п. Наверняка же создатели сервиса имеют доступ к вашему запросу? Невозможно же его прогнать через GPT в зашифрованном виде? На самом деле возможно! Есть алгоритмы «приватного инференса LLM», которые позволяют зашифровать запросы юзера даже от языковой модели, а ответ уже возможно расшифровать только на клиенте пользователя. Пока не буду углубляться, как именно это сделано, скажу только, что ГЛАВНАЯ головная боль таких криптографических протоколов — нелинейности в трансформерах, их тяжело обрабатывать в зашифрованном виде и приходится прибегать к сложнейшим итерационным схемам, раздувающим объём коммуникации в тысячи раз. Выходит, что на генерацию одного токена нужно несколько минут и десятки гигабайтов трафика! Поэтому никто это пока не делает в продакшне, и лучше не спрашивайте у чатгпт, где спрятать труп.
Но помните? У меня была статья про то, что не так уж и нужны нелинейности в трансформерах. Преобразования эмбеддингов от слоя к слою на 99% линейные. Так вот в свежей статье «Entropy-Guided Attention for Private LLMs» авторы попробовали обучить LLM совсем без нелинейностей (оставив только софтмакс). То есть они убрали активации из FF и заменили LayerNorm на линейный аналог. По сути, если бы не этэншн, то трансформер вообще схлопнулся бы в полностью линейную модель и отупел до уровня логистической регрессии.
При такой жёсткой "линеаризации" архитектуры пришлось всего лишь добавить несколько трюков для стабилизации обучения и ШОК: модель нормально обучилась! Небольшие потери в качестве есть, но это крошечная цена за такое упрощение трансформера.
Теперь ждём, что скоро появится нормальное асинхронное шифрование для LLM и OpenAI не узнает, что я спрашиваю у чатгпт и насколько я туп на самом деле.
P.S. Статья классная, но немного обидно, что авторы нас не процитировали.
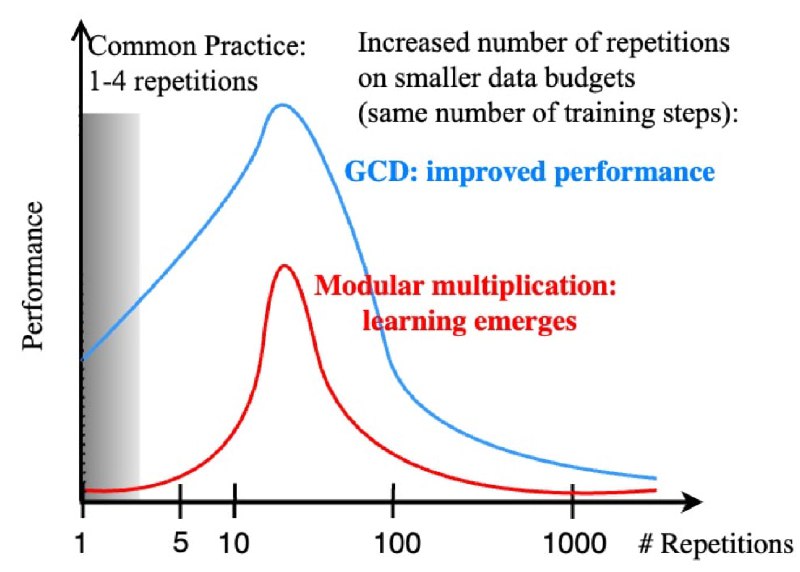
Emergent Properties With Repeated Examples (by FAIR)
Что лучше, прогнать побольше данных за 1 эпоху или взять данных поменьше, но сделать больше эпох (повторений)? Очень актуальный вопрос, учитывая, что доступные текстовые данные скоро закончатся, и LLM по сути прочитают весь интернет. По разным оценкам, сейчас доступно ~90T токенов на английском языке, а для обучения llama-3 уже использовали 15Т — лимит не так уж и далеко.
Похоже, что для трансформеров повторения в обучающих данных могут быть даже полезнее, чем "бесконечное" количество разнообразных данных. Авторы этой статьи изучили как связано качество моделей на синтетических задачах (наибольший общий делитель, умножение по модулю, поиск с.з. матриц) с долей повторений в обучении при фиксированном компьюте. И оказалось, что повторения в датасете критически важны для обучения. Если нет повторений, то некоторые задачи вообще не решаются, сколько бы данных вы ни показывали! Повторения приводят к особому режиму обучения, без которого модель не всегда способна прийти к генерализации. Чем-то напоминает гроккинг, но на гораздо меньшем количестве шагов.
Скорее всего, этот эффект уже активно эксплуатируется при обучении LLM, ведь дублирующихся примеров там и так ооочень много, особенно в коде. Но зато теперь есть повод меньше переживать о дедупликации данных.
Кстати, очень похожий эффект я видел в статье про мультиязычность — там пришли к выводу, что для лучшей работы LLM на нескольких языках сразу, в обучении обязательно должно быть 90% примеров на "доминирующем" языке. Увеличение доли мультиязычных данных выше 10% сильно вредит этой самой мультиязычности.

⚡️Яндекс открыл доступ к более мощному семейству моделей YandexGPT 4
Pro-версия и облегчённая Lite-версия поддерживают более сложные запросы, расширенный контекст, скрытые рассуждения и работу с внешними инструментами. Модели уже доступны через API в Yandex Cloud.
? Pro-версия превосходит предыдущее поколение в 70% случаев, а Lite не уступает лучшей модели прошлого поколения.
? В четыре раза увеличено количество токенов (до 32 тысяч), которое нейросеть может обрабатывать в промте.
? Улучшенная работа с RAG-сценариями и снижение доли галлюцинаций.
? Внедрены скрытые рассуждения (Chain-of-thoughts) для пошагового анализа проблем, выделения этапов и поиска решений.
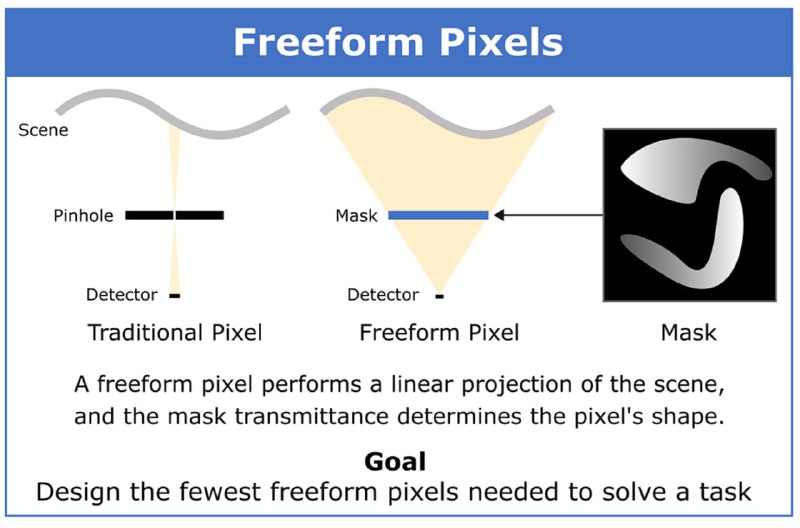
Minimalist Vision with Freeform Pixels
На ECCV-24 была секция, посвящённая низкоуровневому устройству систем компьютерного зрения. По настоящему low-level решение предложили в статье Minimalist Vision with Freeform Pixels, которая получила награду Best Paper Award. Авторы создали прототип полностью автономной по электропитанию камеры.
Вместо обычных матриц в камере используются 24 фотодиода. Перед каждым из них установлена маска-фильтр, которая выступает первым слоем нейросети. Оптическая передаточная функция маски зависит от задачи, под которую обучена камера.
По сути первый слой обеспечивает произвольную форму для каждого пикселя — против фиксированной квадратной у традиционных камер. А последующие слои выводят результат задачи. Так авторы демонстрируют возможность мониторинга рабочего пространства и оценки дорожного трафика при помощи всего лишь 8 пикселей из 24.
Кроме того, камера хорошо показала себя в задаче оценки освещённости помещения. Используя те же 8 пикселей, она сумела определить, какие из источников света были включены в каждый конкретный момент. При этом ни один из источников не был виден камере напрямую — она собирала информацию исходя из состояния помещения.
Помимо низкого энергопотребления, такой подход позволяет обеспечивать конфиденциальность людей в кадре, так как записываемой оптической информации недостаточно для восстановления деталей изображения. Прототип камеры оснащён микроконтроллером с Bluetooth. А с четырёх сторон расположены солнечные панели для получения электроэнергии.
Разбор подготовила *❣ Алиса Родионова*
CV Time
? NVIDIA silently release a Llama 3.1 70B fine-tune that outperforms
GPT-4o and Claude Sonnet 3.5
Llama 3.1 Nemotron 70B Instruct a further RLHFed model on
huggingface
? 85.0 on Arena Hard, 57.6 on AlpacaEval 2 LC, and 8.98 MT-Bench
? Outperforms GPT-4o and Claude 3.5 Sonnet on these benchmarks
? Can accurately answer "How many r's are in strawberry?"
? Based on Llama-3.1-70B-Instruct and trained using RLHF (REINFORCE)
? Released also Llama-3.1-Nemotron-70B-Reward #2 on RewardBench
? Available on Hugging Face and NVIDIA
https://huggingface.co/collections/nvidia/llama-31-nemotron-70b-670e93cd366feea16abc13d8
Community chat: https://t.me/hamster_kombat_chat_2
Website: https://hamster.network
Twitter: x.com/hamster_kombat
YouTube: https://www.youtube.com/@HamsterKombat_Official
Bot: https://t.me/hamster_kombat_bot
Last updated 12 months ago
Your easy, fun crypto trading app for buying and trading any crypto on the market.
📱 App: @Blum
🤖 Trading Bot: @BlumCryptoTradingBot
🆘 Help: @BlumSupport
💬 Chat: @BlumCrypto_Chat
Last updated 1 year, 5 months ago
Turn your endless taps into a financial tool.
Join @tapswap_bot
Collaboration - @taping_Guru
Last updated 1 year ago