yet another dev

Очередной канал обычного бэкенд разработчика живущего в Сербии 🇷🇸
Связь: @alexeyfv

Официальный новостной канал криптобиржи OKX | www.okx.com на русском языке.
💬 Комьюнити: t.me/okx_russian
👨💻 Поддержка: [email protected]
АДМИН: @DaniiOKX
Маркетинг: @CoffeeTrends
Last updated 1 month ago

Here in simple language about TON and crypto
Founder: @metasalience
contact : @deftalk_bot
Last updated 4 months ago

Канал о TON и все что с ним связано:
1. Аналитика
2. Инсайды
3. Авторское мнение
Ведро для спама: @ton_telegrambot
Бот с курсами криптовалют: @TonometerBot
Чат: @chaTON_ru
Админ: @filimono
Last updated 1 month ago
EventFlow – опенсорс библиотека для DDD, Event Sourcing и CQRS
Немного отвлечёмся от бенчмарков. Уже 2 недели работаю над pet-проектом с DDD + ES + CQRS. Для этого искал подходящую библиотеку, т.к. хотелось сосредоточиться на бизнес-проблемах, а не изобретать велосипед. Нашёл фреймворк EventFlow. В библиотеке есть всё готовое:
- базовые классы для агрегатов и доменных событий;
- команды, запросы;
- обработчики команд, запросов, событий;
- функционал для паттерна «сага»;
- функционал для миграций событий.
и многое другое.
Документация написана достаточно подробно, главное внимательно читать. Я, например, проглядел, что по умолчанию фреймворк «проглатывает» исключения, выброшенные в хэндлерах команд. Из-за этого долго не мог понять, почему некоторые тестовые моки интерфейсов выбрасывают исключения, но это не приводит к поломке тестов.
Альтернативы
В процессе поиска нашёл несколько других проектов по теме. Возможно, кому-то пригодится, поэтому делюсь списком.
- Revo – ещё одна библиотека для DDD, Event Sourcing и CQRS. Изначально я попытался запустить проект именно с ней, но мне она не понравилась по нескольким причинам:
- Проект крэшился сразу после запуска. Связано это с тем, что Revo построен вокруг Ninject – сторонней библиотеки для внедрения зависимостей, а не встроенного в .NET DI. Исправить я это не смог, из-за плохо написанной документации.
- Функционал библиотеки разбит на множество Nuget-пакетов. Пришлось несколько раз возвращаться к документации, чтобы понять какой очередной пакет установить, чтобы проект наконец-то уже собрался.
У проекта много звёзд, так что, возможно, библиотека не так плоха, а это я не смог разобраться. 🤷♂️
-
Marten DB – Event Store построенный вокруг PostgreSQL. Подходит, если вы хотите самостоятельно разработать базовые классы для агрегатов, событий, команд, запросов, шин сообщений и т. д.
-
YesSQL – интерфейс, имитирующий документоориентированную БД. Библиотека построена поверх EF Core и работает c SQLite, PostgreSQL, SQL Server и MySQL. Думаю, что тоже подходит для создания Event Store.
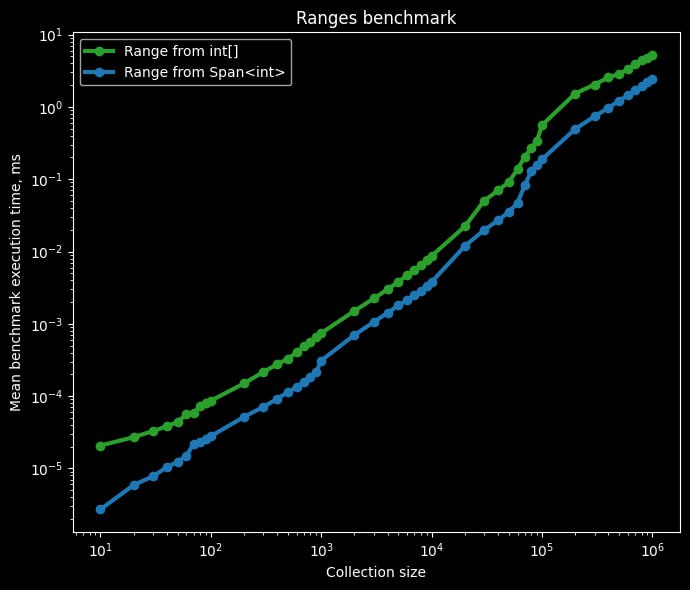
Используйте диапазоны (Range) только со Span
В предыдущем посте я писал о скрытой аллокации, возникающей из-за упаковки энумератора. В этом посте расскажу об ещё одной скрытой аллокации.
5 лет назад в C# 8.0 появились индексы и диапазоны, которые позволяют получать часть коллекции с помощью удобного синтаксиса. Например, в следующем примере из массива извлекаются все элементы, кроме 2-х первых и 2-х последних:
int[] arr = [1, 2, 3, 4, 5, 6];
var subarr = arr[2..^2]; // [3, 4]
Это удобно, особенно по сравнению с аналогичной записью через LINQ:
var subarr = arr.Skip(2)
.Take(arr.Length \- 2 \- 2)
.ToArray();
В случае с LINQ мы явно создаём массив с помощью метода ToArray. Однако это можно и не делать, если нужно просто пройтись по выбранным элементам.
Теперь посмотрим на C#-код без синтаксического сахара. При использовании с массивом оператор диапазона всегда создаёт новый массив. При компиляции он преобразуется в вызов RuntimeHelpers.GetSubArray, который и создаёт новый массив.
// int[] subarr = arr[2..^2]
int[] subArray = RuntimeHelpers
.GetSubArray(array, new Range(2,
new Index(2, true)));
Если нет необходимости сохранять подмассив, лучше вызвать AsSpan() перед использованием диапазонов.
```
// Исходный код
int[] arr = [1, 2, 3, 4, 5, 6];
var subarr = arr.AsSpan()[2..^2]; // [3, 4]
// После компиляции
Span span = MemoryExtensions.AsSpan(array);
Span subarr = span.Slice(2,
span.Length - 2 - 2);
```
С точки зрения производительности, создание нового массива и копирование элементов – это затратная операция, особенно в сравнении со слайсами спанов, которые выполняются практически мгновенно. Рассмотрим следующий код:
start = Length / 4;
end = Length * 3 / 4;
var sum = 0;
// 2\-3 times faster:
// \_transactionsArray.AsSpan()[\_start..\_end];
var sliced = \_transactionsArray[start..end];
foreach (var t in sliced) sum += t.Amount;
return sum;
Добавление AsSpan() перед использованием оператора диапазона позволяет сократить время выполнения в среднем в 2-3 раза (см. график).
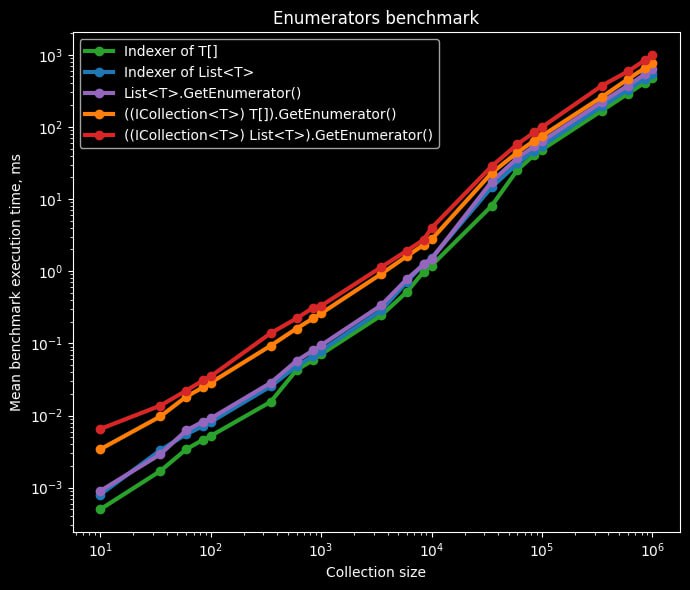
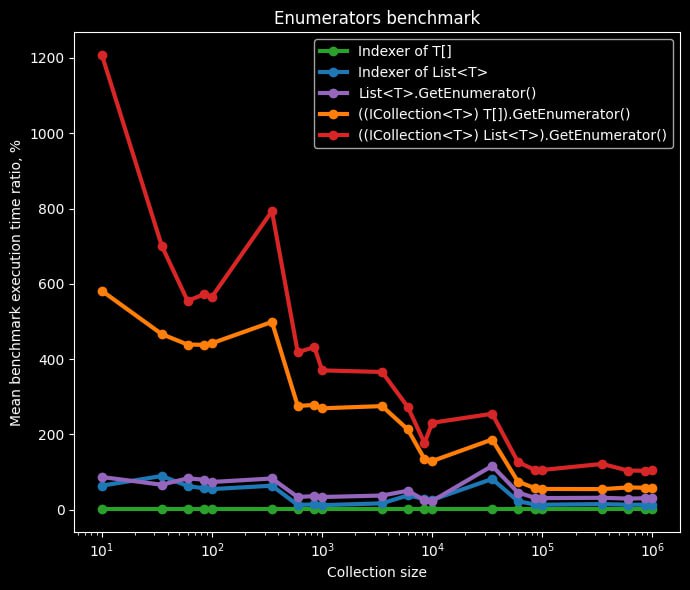
👩💻 Пишем производительный C# код при работе с коллекциями
Публикую следующую часть статьи про производительность коллекций. Сегодня про Enumerator.
---
Предположим, у нас есть массив _transactionsArray и список _transactionsList. Сама транзакция выглядит следующим образом:
public record class Transaction(
Guid Id,
int Amount,
string Description);
Существует множество способов пройтись по двум вышеупомянутым коллекциям:
```
// Индексатор массива
var sum = 0;
for (var i = 0; i < _transactionsArray.List; i++) {
sum += _transactionsArray[i].Amount;
}
// Индексатор списка
var sum = 0;
for (var i = 0; i < _transactionsList.Count; i++) {
sum += _transactionsList[i].Amount;
}
// Энумератор IEnumerable
var sum = 0;
var collection = (IEnumerable)_transactionsArray;
foreach (var item in collection) {
sum += item.Amount;
}
var sum = 0;
var collection = (IEnumerable)_transactionsList;
foreach (var item in collection) {
sum += item.Amount;
}
// Энумератор List
var sum = 0;
foreach (var item in _transactionsList) {
sum += item.Amount;
}
```
Один из этих способов аллоцирует больше памяти, чем остальные – это приведение _transactionsList к IEnumerable. Причина кроется в реализации энумератора для списков. У типа List есть собственный энумератор-структура.
Если использовать foreach с типом List, то проблем не возникает. Компилятор C# сгенерирует код, который будет использовать эту структуру напрямую.
```
// Исходный код
var nums= new List();
var sum = 0;
foreach (n in nums) sum +=n;
// Код после компиляции
var nums = new List();
var num = 0;
List.Enumerator enumerator =
nums.GetEnumerator();
while (enumerator.MoveNext()) {
num += enumerator.Current;
}
```
Но если привести List, например, к IList или IReadOnlyList, т.е. к любому интерфейсу, реализующему IEnumerable, то произойдёт неявная упаковка List.Enumerator. Это происходит из-за того, что IEnumerable.GetEnumerator() возвращает интерфейс IEnumerator.
```
// Исходный код
var nums = new List();
var collection = (IEnumerable) nums;
var sum = 0;
foreach (n in collection) sum +=n;
// Код после компиляции
var nums = new List();
var collection = ((IEnumerable)nums);
var num = 0;
IEnumerator.Enumerator enumerator =
// упаковка
collection.GetEnumerator();
while (enumerator.MoveNext()) {
num += enumerator.Current;
}
```
Аналогичный подход с энумераторами также встречается и других коллекциях: LinkedList, Stack, Queue и т.д. Исключением являются, например, массивы.
Насколько упаковка влияет на производительность можно понять из графиков. Бенчмарк 100 раз прошёлся по каждой из коллекции. На первом графике ось Y отображает проценты от бенчмарка с массивом, а на втором — миллисекунды. Шкала оси X в обоих случаях логарифмическая.
Если говорить об абсолютных значениях, разница не так велика — десятки миллисекунд для коллекций размером 100 000 элементов и более. Наибольшее коварство такое поведение представляет, когда у вас много небольших коллекций. Я в своей практике встречал проблему, когда упаковка энумератора приводила к аллокациям десятков и сотен мегабайт. Это было большое дерево директорий, а доступ к дочерним директориям был только через IReadOnlyList.

*👩💻 *Пишем производительный С# код при работе с коллекциями
Сейчас я работаю над статьёй о том, как писать производительный код для работы с коллекциями. В ней будут как базовые советы для начинающих программистов, так и продвинутые. Поскольку статья ещё не готова, держите мем и фрагмент, посвящённый LINQ.
---
В большинстве случаев методы LINQ работают медленнее и используют больше памяти. Это не значит, что LINQ – это плохо. Нет, это очень крутая фича C# и, естественно, я её тоже использую. Однако в некоторых и, подчеркну, редких ситуациях для лучшей производительности стоит писать в императивном стиле. Рассмотрим несколько простых примеров.
Select vs ConvertAll vs императивный стиль
Предположим, у нас есть массив транзакций:
public record class Transaction(
Guid Id,
int Amount,
string Description);
Допустим, нужно получить поле Description для всех элементов массива _transactions. Неважно, зачем нам это, — просто нужно. 🙂 Это можно сделать с помощью Array.ConvertAll, методов Select и ToArray, или вручную. Сравним эти три способа.
```
// Benchmark 1
Array.ConvertAll(_transactions,
x => x.Description);
// Benchmark 2
_transactions
.Select(x => x.Description)
.ToArray();
// Benchamrk 3
var array = new string[_transactions.Length];
for (int i = 0; i < _transactions.Length; i++) {
array[i] = _transactions[i].Description;
}
// Results
| Method | Mean | Ratio |
|------------------ |-----------:|---------:|
| ArrayConvertAll | 1,296.4 μs | -3% |
| LinqSelect | 1,343.4 μs | baseline |
| ImperativeConvert | 1,250.4 μs | -7% |
```
Array.ConvertAll работает на 3% быстрее, чем LINQ, а императивный стиль — на 7% быстрее. Да, разница небольшая, но методы LINQ часто используются последовательно, и в итоге суммарное отличие в производительности может оказаться более заметным.
Any vs Exists vs императивный стиль
Рассмотрим второй пример — проверка существования элемента в массиве.
```
// Benchmark 1
return Array.Exists(_transactions,
x => x.Amount > 1_000_00);
// Benchmark 2
return _transactions
.Any(x => x.Amount > 1_000_00);
// Benchmark 3
foreach (var t in _transactions) {
if (t.Amount > 1_000_000) return true;
}
return false;
// Results
| Method | Mean | Ratio |
|------------------ |-----------:|---------:|
| ArrayExists | 567.9 μs | -39% |
| LinqAny | 926.1 μs | baseline |
| ImperativeExists | 488.5 μs | -47% |
```
Array.Exists работает на 39% быстрее, чем LINQ, а императивный стиль — почти вдвое быстрее.
---
Я обязательно проверю и другие методы, а также протестирую с массивами разного размера. Но что-то мне подсказывает, что этот раздел будет называться «Избегайте LINQ».
Кстати, напишите в комментариях, с какими проблемами производительности вам приходилось сталкиваться при работе с коллекциями. Если этого ещё нет в статье, я проанализирую, сделаю бенчмарки и включу разбор в статью.

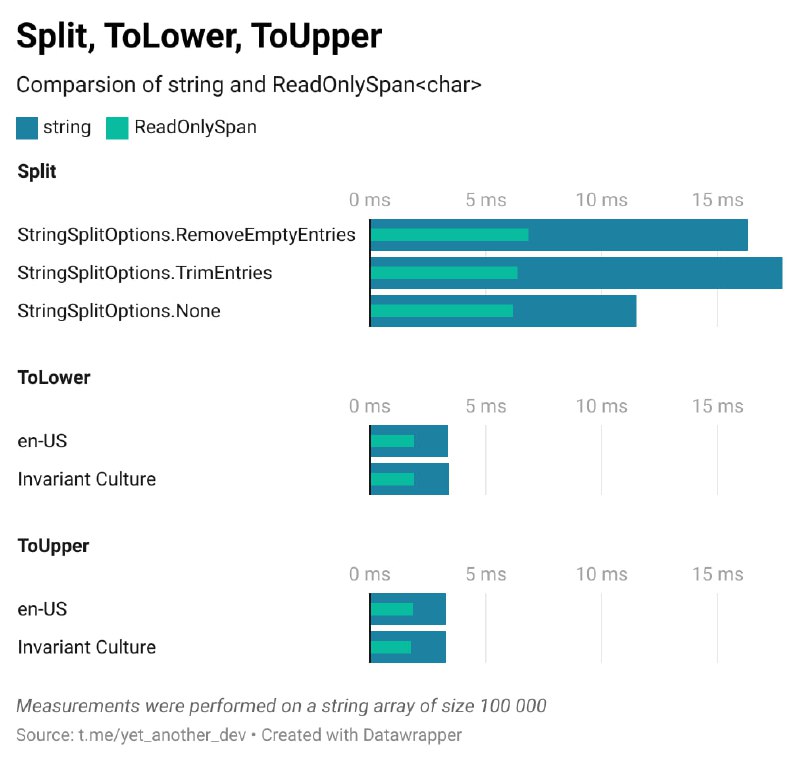
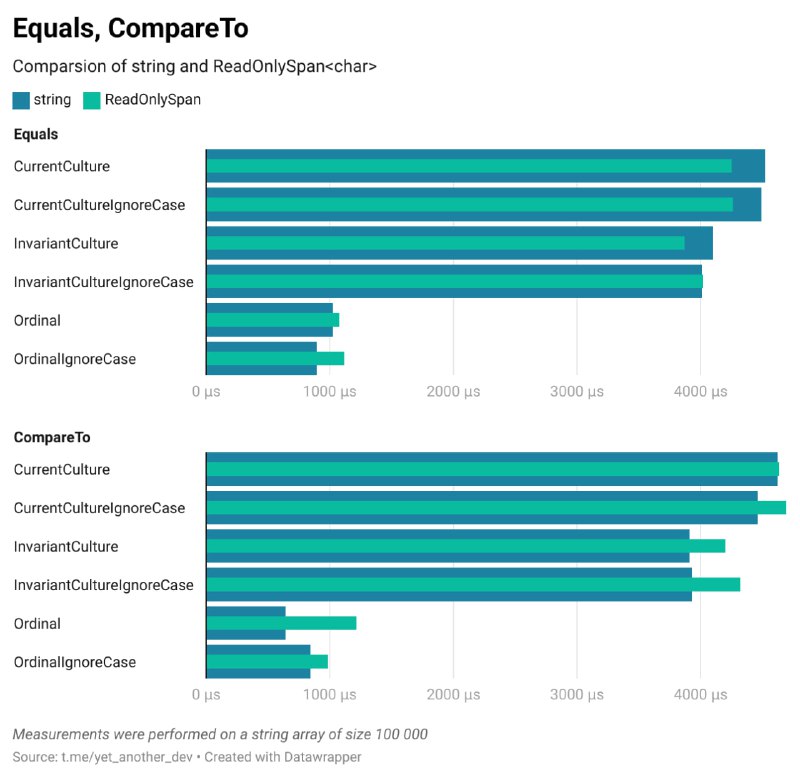
🖥 Сравнение string и Span. Часть 3. CopyTo, Split, Replace, ToLower, ToUpper
English version is below.
Продолжаю сравнивать методы string и ReadOnlySpan.
Метод Split работает на 46% – 64% быстрее в ReadOnlySpan. Использование метода MemoryExtensions.Split позволяет работать со структурой Range, массив которых можно создать в стеке:
Span<Range> ranges = stackalloc Range[str.Length];
str.AsSpan().Split(ranges, separator);
Методы ToLower и ToUpper также работают на 43% – 45% быстрее в ReadOnlySpan. И опять же, это преимущество достигается за счёт отсутствия аллокаций в куче:
Span<char> destination = stackalloc char[str.Length];
str.AsSpan().ToLower(destination, CultureInfo.InvariantCulture);
Производительность метода CopyTo практически одинаковая — разница составляет всего 3% в пользу ReadOnlySpan. Однако важно учитывать, что массив, в который будет скопирована строка, должен быть заранее проинициализирован. Это можно сделать как в стеке с помощью stackalloc, так и в куче с помощью оператора new, что может влиять на производительность:
```
// Вариант 1
Span destination = new char[str.Length];
str.CopyTo(destination);
// Вариант 2
Span destination = stackalloc char[str.Length];
str.CopyTo(destination);
```
Метод Replace в ReadOnlySpan работает на 75% быстрее, чем в string. Это очевидно связано с отсутствием аллокаций при использовании ReadOnlySpan — результат замены сохраняется в отдельный Span:
Span<char> destination = stackalloc char[str.Length];
str.AsSpan().Replace(destination, oldChar, newChar);
👩💻 Код и результаты
🖥 String and Span comparison. Part 3. CopyTo, Split, Replace, ToLower, ToUpper
I continue to compare the string and ReadOnlySpan methods.
The Split method works 46% – 64% faster with ReadOnlySpan. Using the MemoryExtensions.Split method allows to work with Range. An array of ranges can be created on the stack:
Span<Range> ranges = stackalloc Range[str.Length];
str.AsSpan().Split(ranges, separator);
The ToLower and ToUpper methods are also 43% – 45% faster with ReadOnlySpan. Again, this comes from avoiding allocations on a heap:
Span<char> destination = stackalloc char[str.Length];
str.AsSpan().ToLower(destination, CultureInfo.InvariantCulture);
Method CopyTo has almost the same performance — ReadOnlySpan is only 3% faster. However, it's important to note that the destination array should be pre-initialized. This can be done either on the stack using stackalloc or on the heap using the new operator, which can affect performance:
```
// Option 1
Span destination = new char[str.Length];
str.CopyTo(destination);
// Option 2
Span destination = stackalloc char[str.Length];
str.CopyTo(destination);
```
Method Replace in ReadOnlySpan is 75% faster than in string. Again, this is due to the absence of heap allocations when using ReadOnlySpan:
Span<char> destination = stackalloc char[str.Length];
str.AsSpan().Replace(destination, oldChar, newChar);
👩💻 Code and results
Официальный новостной канал криптобиржи OKX | www.okx.com на русском языке.
💬 Комьюнити: t.me/okx_russian
👨💻 Поддержка: [email protected]
АДМИН: @DaniiOKX
Маркетинг: @CoffeeTrends
Last updated 1 month ago
Here in simple language about TON and crypto
Founder: @metasalience
contact : @deftalk_bot
Last updated 4 months ago
Канал о TON и все что с ним связано:
1. Аналитика
2. Инсайды
3. Авторское мнение
Ведро для спама: @ton_telegrambot
Бот с курсами криптовалют: @TonometerBot
Чат: @chaTON_ru
Админ: @filimono
Last updated 1 month ago